What is the next stop for deep learning? No major breakthroughs in the field of algorithms
What is the next stop for deep learning? Last year, there was no major breakthrough in the field of algorithms. The author, William Vorhies, is the editorial director of DataScienceCentral. He served as president and chief data scientist at Data-Magnum and president of EB5C. He surveyed several leading technologies that are expected to make the next breakthrough in the field.
We are stuck, or at least we are in a bottleneck.
Who remembers that the last time in the algorithm, chip or data processing field, there was no significant and significant progress? It was too unusual for me to attend the Strata San Jose Conference a few weeks ago without seeing compelling new developments.
As I reported before, we seem to have entered a mature phase, and now our main focus is to ensure that all powerful new technologies work well together (integration platforms) or to reap the rewards of large-scale venture capital.
It’s not just me who noticed this problem. The views of several participants and exhibitors are very similar to me. One day I received a research summary from several well-known researchers who have been evaluating the relative merits of different advanced analytics platforms and concluded that there are no different places worth reporting.

Why are we stuck? Where is the card?
Our current situation is not really bad. In the past two or three years, we have made progress in the field of deep learning and intensive learning. Deep learning brings us great features in handling speech, text, images and video. Together with intensive learning, we have made significant progress in games and autonomous car pen robots.
We are now in the early stages of commercial explosive development based on these technologies, such as greatly simplifying customer interaction through chat bots, new personal convenience applications (such as personal assistants and Alexa), and secondary automation in private cars (such as adaptive Cruise control, avoid accident braking and lane maintenance).
Tensorflow, Keras, and other deep learning platforms are easier to use than ever, and thanks to the GPU, they are more efficient than ever.
However, a series of known shortcomings have not been solved at all.
Need too much labeled training data.
Models take too long or too much expensive resources to train, but there may still be no training at all.
Especially the hyperparameters in terms of nodes and layers are still mysterious. Automated or even widely accepted rules of thumb are still in the foreseeable future.
Migration learning only means moving from complex to simple, rather than migrating from one logical system to another.
I am sure there are more questions. Our card is stuck to solve these major shortcomings.
What makes us stop?
Taking the deep neural network (DNN) as an example, the traditional view at the moment is that if we continue to advance and continue to invest, these shortcomings will be overcome. For example, from the 1980s to the 2000s, we knew how to make DNN work, but there was no corresponding hardware at all. Once this problem is overcome, DNN combined with the new open source concept will break the bottleneck in this new field.
All types of research have their own development momentum, especially, once you invest a lot of time and money in a particular direction, you will continue to move in this direction. If you have spent years developing expertise in these skills, it won't change easily.
Change direction even if you are not completely sure what is the right direction
Sometimes we need to change direction, even if we don't know exactly what the new direction is. This is what the leading Canadian and American AI researchers have done recently. They think they are misled and need to start over.

Last fall, Geoffrey Hinton interprets this sentiment with practical action, and he became famous for his pioneering work in the field of DNN in the 1980s. Sinton is now an Emeritus Professor and a Google researcher at the University of Toronto. He said that he is now "extremely suspicious" about DNN's basic approach: backpropagation. Hinton observed that the human brain does not need all the data of those markers to come to a conclusion, saying, "My point is, throw away the backpropagation and start from scratch."
With this in mind, let's briefly investigate the new directions. They are very reliable and some are not realistic, but they are not incremental improvements to the deep neural network we know.
The content described is intended to be short and will undoubtedly lead you to further reading for a full understanding.
Technology that looks like DNN but is not.
There is a series of researches that strongly slam the idea of ​​backpropagation and believe that the basic structure of nodes and layers is useful, but the methods of connection and calculation need to be greatly modified.
Capsule Network (CapsNet)
Let's start with Sinton's current research direction, CapsNet. This is related to CNN's image classification; in a nutshell, the problem is that the Convolutional Neural Network (CNN) is not sensitive to the pose of the object. That is to say, if you identify the same object, but the position, size, direction, deformation, speed, reflectivity, hue and texture are different, you need to add training data for each of these situations.
In CNN, this is handled by a large increase in training data and/or an increase in the maximum pooling layer that can be generalized, but the actual information is completely lost.

The following description is from one of the many excellent technical descriptions of CapsNets, from Hackernoon.
A capsule is a set of nested neural layers. So in a normal neural network, you are constantly adding more layers. In CapsNet, you add more layers to a layer. Or in other words, nest a neural layer inside another neural layer. The state of the neurons within the capsule captures the above attributes of an entity within the image. The capsule outputs a vector indicating the presence of the entity. The direction of the vector represents the attributes of the entity. This vector is sent to all possible parent nodes in the neural network. The prediction vector is calculated by multiplying its own weight and the weight matrix. No matter which parent has the largest scalar prediction vector product, the capsule bond is increased, and the remaining parent nodes reduce the capsule key. This approach using routing by agreement is superior to current mechanisms like maximum pooling.
CapsNet has greatly reduced the required training set, and in early tests it showed that performance is superior in image classification.
gcForest
In February of this year, we introduced the research results of Zhou Zhihua and Feng Wei of the State Key Laboratory of New Software Technology of Nanjing University. They showed a technology called gcForest. Their research papers show that gcForest often outperforms CNN and RNN in text classification and image classification. The advantages are quite obvious.
Only a small amount of training data is needed.
It runs on regular desktop CPU devices without the need for a GPU.
Training is as fast as it is, and in many cases even faster, suitable for distributed processing.
The hyperparameters are much less and perform well under the default settings.
Rely on a random forest that is easy to understand, rather than a deep neural network that is completely opaque.
In short, gcForest (Multi-Grain Cascading Forest) is a decision tree integration method in which the cascading structure of deep networks is preserved, but opaque edges and node neurons are random forest groups paired with completely random tree forests. Replace it. For more information on gcForest, please join us in this original article (https://).
Pyro and Edward
Pyro and Edward are two new programming languages ​​that combine deep learning frameworks with probabilistic programming. Pyro is a masterpiece of Uber and Google, and Edward was born out of Columbia University and funded by the Defense Advanced Research Projects Agency (DARPA). As a result, the framework allows deep learning systems to measure how confident they are in forecasting or making decisions.
In classical predictive analysis, we may use logarithmic loss as a fitting function and punish confident but erroneous predictions (false positives) to deal with this problem. So far, there is no inevitable result for deep learning. (So ​​far there's been no corollary for deep learning.)
For example, this is expected to apply to autonomous vehicles or airplanes so that the control system has some sense of confidence or suspicion before making a major decision. This of course is what you want Uber's self-driving vehicles to know before you get on the bus.
Both Pyro and Edward are in the early stages of development.
It doesn't look like a deep network approach
I often come across small companies that develop platforms that use unusual algorithms at their core. I have found that in most cases, they have been reluctant to provide enough detailed information so that I can describe the overview of the platform algorithm for the reader. This kind of secrecy does not affect their utility, but unless they provide some benchmark numbers and some details, I can't really tell you what's going on inside.
Currently, the most advanced non-DNN algorithms and platforms I have studied are as follows:
Layered time memory (HTM)
Hierarchical Time Memory (HTM) uses sparse distributed representation (SDR) to model brain neurons and perform computations, performance in scalar prediction (future value in commodity, energy, or stock price) and anomaly detection More than CNN and RNN.
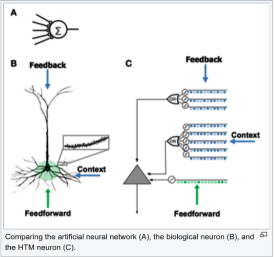
This is the result of Jeff Hawkins, famous for his Palm Pilot, in his company Numenta. Hawkins is committed to creating a powerful AI model based on fundamental research on brain function, which is not the structure of layers and nodes in DNN.
HTM is characterized by the ability to discover patterns very quickly, requiring only 1000 observations. In contrast, training CNN or RNN requires hundreds of thousands or even millions of observations.
In addition, pattern recognition is unsupervised and can be used to identify changes in the pattern based on changing inputs in real time and to extend it. The resulting system is not only very fast to train, but also self-learning and adaptive, and is not plagued by data changes or interference.
We introduced HTM and Numenta in our February article, so I suggest you read it (https://).
Some progressive improvements worth mentioning
We are trying to focus on technologies that really change the field, but at least two examples of incremental improvements are worth mentioning. These are obviously still typical of CNN and RNN (with elements of backpropagation), but work better.
Network pruning using Google Cloud AutoML
Researchers at Google and Nvidia use a method called network pruning to remove neurons that do not directly affect the output, making the neural network smaller and more efficient to run. This recent advancement is due to a significant improvement in the performance of Google's new AutoML platform.
Transformer
Transformer is a novel approach that was originally useful in areas where CNN, RNN, and LTSM excel: language processing (such as language-to-language translation). Last summer, researchers at Google Brain and the University of Toronto released Transformer, which has shown significant improvements in many tests including the English/German translation test.
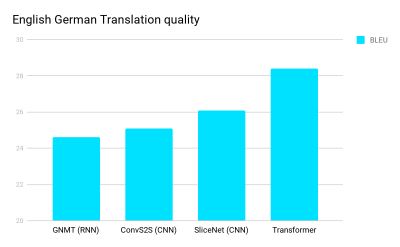
RNN has the characteristics of sequential processing, making it more difficult to take full advantage of the performance of modern fast computing devices such as GPUs, which are good at parallel processing rather than sequential processing. The sequential processing characteristics of CNN are much weaker than RNN, but in the CNN architecture, the number of steps required to combine information from the input distal portion still increases with distance.
The breakthrough in accuracy comes from the development of a “self-attention function†that significantly simplifies the steps into a small number of constant steps. At each step, it uses a self-attention mechanism to model the relationships between all the words in a sentence, regardless of their respective locations.
Please read the original research paper here (https://papers.nips.cc/paper/7181-attention-is-all-you-need.pdf).
Conclusion: Maybe it's time to change direction.
One fact that cannot be ignored is that China is investing heavily in AI; the goal is to surpass the United States in a few years and become a global AI leader.
Steve LeVine is the editor of the future column of Axios and teaches at Georgetown University. In an article he wrote, China believes that China may follow quickly, but I am afraid it will never catch up. The reason is that researchers in the US and Canada can change direction and start from scratch. Institutionally oriented Chinese can never do this. The following is from the article by Levin:
“In China, that’s unimaginable,†said Manny Medina, CEO of Seattle Outreach.io. He said that the stars of the AI ​​world like Facebook's Yann LeCun and Toronto's Vector Institute's Geoff Hinton "do not need approval. They can start research and move forward." â€
As venture capitalists say, it may be time to change direction.
RAndM Disposable Vape,Vape RANDM,Vape
Shenzhen Essenvape Technology Co., Ltd. , https://www.essenvape.com