Normal worker_pool detailed creation process code analysis
Since the kernel's workqueue changes have been happening, the general kernel books are old and can't keep up with the times.
Workqueue is a very important mechanism in the kernel, especially the kernel driver. The general small work will not be handled by one thread but thrown into Workqueue. The main job of Workqueue is to use the process context to handle a large number of small tasks in the kernel.
This article's code analysis is based on the Linux kernel 3.18.22, the best way to learn is "read the fucking source code"
1. Several basic concepts of CMWQ
Several concepts about workqueue are work-related data structures that are very confusing and probably understand this:
Work : work.
Workqueue : A collection of work. Workqueue and work are one-to-many relationships.
Worker: Worker. In the code, the worker corresponds to a work_thread() kernel thread.
Worker_pool: A collection of workers. Worker_pool and worker are one-to-many relationships.
Pwq(pool_workqueue): Man-in-the-middle/intermediary, responsible for establishing the relationship between workqueue and worker_pool. Workqueue and pwq are one-to-many relationships, and pwq and worker_pool are one-to-one relationships.
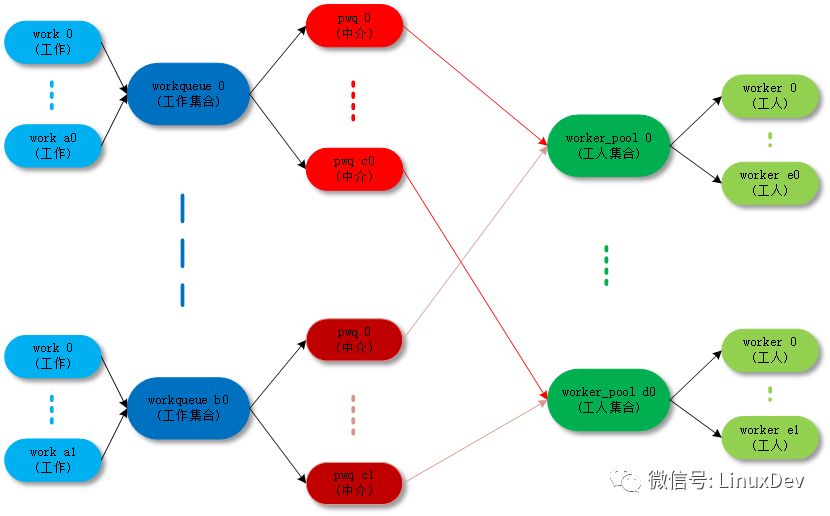
The ultimate goal is to pass the work (work) to the worker. The purpose of the intermediate data structure and various relationships is to organize the matter more clearly and efficiently.
1.1 worker_pool
Each thread that executes work is called a worker, and a set of workers is called worker_pool. The essence of CMWQ is manage_workers() on the dynamic increase/decrease management of workers in worker_pool.
CMWQ divides worker_pool into two categories:
Normal worker_pool, used by the general workqueue;
Unbound worker_pool, used for WQ_UNBOUND type workqueue;
1.1.1 normal worker_pool
The default work is handled in the normal worker_pool. The system's plan is to create two normal worker_pools per CPU: a normal priority (nice=0) and a high priority (nice=HIGHPRI_NICE_LEVEL). The process corresponding to the created worker is not the same.
Each worker corresponds to a worker_thread() kernel thread. A worker_pool contains one or more workers. The number of workers in the worker_pool is dynamically increased or decreased according to the workload of the worker in the worker_pool.
We can use the ps | grep kworker command to view the kernel threads for all workers. The naming rules for the normal worker_pool kernel threads (worker_thread()) are:
Snprintf(id_buf, sizeof(id_buf), "%d:%d%s", pool->cpu, id, pool->attrs->nice < 0 ? "H" : "");worker->task = kthread_create_on_node (worker_thread, worker, pool->node, "kworker/%s", id_buf);
So similar name is normal worker_pool:
Shell@PRO5:/$ps | grep "kworker"root 14 2 0 0 worker_thr 0000000000 Skworker/1:0H// cpu1 0th worker process of high priority worker_pool root 17 2 0 0 worker_thr 0000000000 S kworker/2: 0// cpu2 0 worker worker of low priority worker_pool root 18 2 0 0 worker_thr 0000000000 Skworker/2:0H// cpu2 0 worker worker of high priority worker_pool root 23699 2 0 0 worker_thr 0000000000 S kworker/ 0:1// cpu0 1st worker process of low priority worker_pool
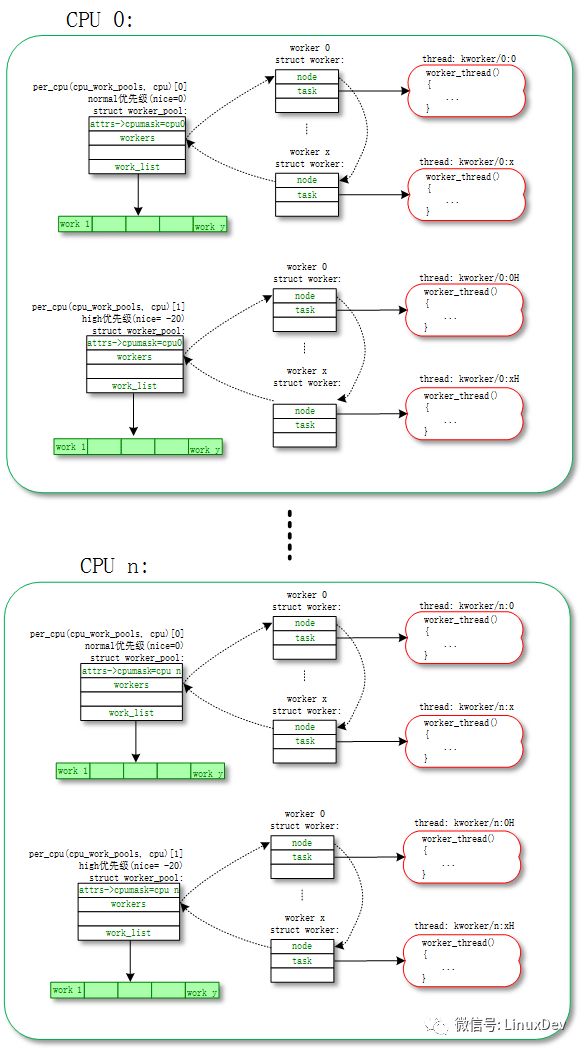
The corresponding topology is as follows:
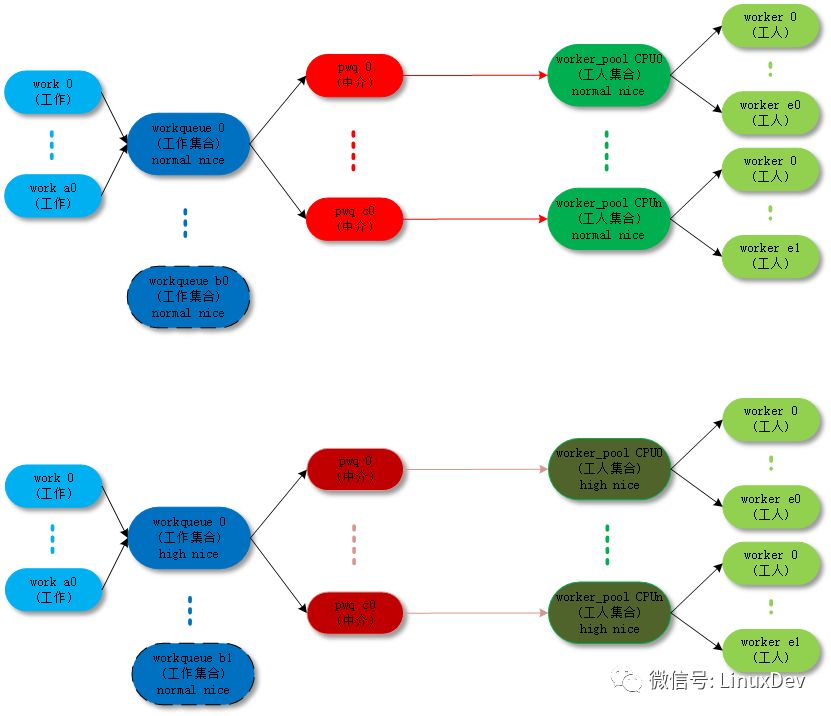
The following is a detailed analysis of the normal worker_pool creation process code:
Kernel/workqueue.c:
Init_workqueues() -> init_worker_pool()/create_worker()
Static int __init init_workqueues(void)
{
Int std_nice[NR_STD_WORKER_POOLS] = { 0, HIGHPRI_NICE_LEVEL };
Int i, cpu;
// (1) Create a corresponding worker_pool for each cpu
/* initialize CPU pools */
For_each_possible_cpu(cpu) {
Struct worker_pool *pool;
i = 0;
For_each_cpu_worker_pool(pool, cpu) {
BUG_ON(init_worker_pool(pool));
// specify cpu
Pool->cpu = cpu;
Cpumask_copy(pool->attrs->cpumask, cpumask_of(cpu));
// Specifies the process priority nice
Pool->attrs->nice = std_nice[i++];
Pool->node = cpu_to_node(cpu);
/* alloc pool ID */
Mutex_lock(&wq_pool_mutex);
BUG_ON(worker_pool_assign_id(pool));
Mutex_unlock(&wq_pool_mutex);
}
}
// (2) Create the first worker for each worker_pool
/* create the initial worker */
For_each_online_cpu(cpu) {
Struct worker_pool *pool;
For_each_cpu_worker_pool(pool, cpu) {
Pool->flags &= ~POOL_DISASSOCIATED;
BUG_ON(!create_worker(pool));
}
}
}
| →
Static int init_worker_pool(struct worker_pool *pool)
{
Spin_lock_init(&pool->lock);
Pool->id = -1;
Pool->cpu = -1;
Pool->node = NUMA_NO_NODE;
Pool->flags |= POOL_DISASSOCIATED;
// (1.1) worker_pool's work list, each workqueue mounts work to this linked list,
// Execute multiple workers corresponding to worker_pool
INIT_LIST_HEAD(&pool->worklist);
// (1.2) worker_pool's idle worker list,
// When the worker does not work, it will not be destroyed immediately. Enter the idle state first
INIT_LIST_HEAD(&pool->idle_list);
// (1.3) worker_pool's busy worker list,
// The worker is working and doing work
Hash_init(pool->busy_hash);
// (1.4) Check if the idle state worker needs a destroy timer
Init_timer_deferrable(&pool->idle_timer);
Pool->idle_timer.function = idle_worker_timeout;
Pool->idle_timer.data = (unsigned long)pool;
// (1.5) A timer that checks for timeouts when worker_pool creates a new worker
Setup_timer(&pool->mayday_timer, pool_mayday_timeout,
(unsigned long)pool);
Mutex_init(&pool->manager_arb);
Mutex_init(&pool->attach_mutex);
INIT_LIST_HEAD(&pool->workers);
Ida_init(&pool->worker_ida);
INIT_HLIST_NODE(&pool->hash_node);
Pool->refcnt = 1;
/* shouldn't fail above this point */
Pool->attrs = alloc_workqueue_attrs(GFP_KERNEL);
If (!pool->attrs)
Return -ENOMEM;
Return 0;
}
| →
Static struct worker *create_worker(struct worker_pool *pool)
{
Struct worker *worker = NULL;
Int id = -1;
Char id_buf[16];
/* ID is needed to determine kthread name */
Id = ida_simple_get(&pool->worker_ida, 0, 0, GFP_KERNEL);
If (id < 0)
Goto fail;
Worker = alloc_worker(pool->node);
If (!worker)
Goto fail;
Worker->pool = pool;
Worker->id = id;
If (pool->cpu >= 0)
// (2.1) Construct a process name for the normal worker_pool worker
Snprintf(id_buf, sizeof(id_buf), "%d:%d%s", pool->cpu, id,
Pool->attrs->nice < 0 ? "H" : "");
Else
// (2.2) Constructor process name for unbound worker_pool
Snprintf(id_buf, sizeof(id_buf), "u%d:%d", pool->id, id);
// (2.3) Create the kernel process for the worker
Worker->task = kthread_create_on_node(worker_thread, worker, pool->node,
"kworker/%s", id_buf);
If (IS_ERR(worker->task))
Goto fail;
// (2.4) Set the corresponding priority of the kernel process nice
Set_user_nice(worker->task, pool->attrs->nice);
/* prevent userland from meddling with cpumask of workqueue workers */
Worker->task->flags |= PF_NO_SETAFFINITY;
// (2.5) Bind worker and worker_pool
/* successful, attach the worker to the pool */
Worker_attach_to_pool(worker, pool);
// (2.6) Set the worker's initial state to idle,
// After worker wake_up_process, worker automatically leave idle state
/* start the newly created worker */
Spin_lock_irq(&pool->lock);
Worker->pool->nr_workers++;
Worker_enter_idle(worker);
Wake_up_process(worker->task);
Spin_unlock_irq(&pool->lock);
Return worker;
Fail:
If (id >= 0)
Ida_simple_remove(&pool->worker_ida, id);
Kfree(worker);
Return NULL;
}
|| →
Static void worker_attach_to_pool(struct worker *worker,
Struct worker_pool *pool)
{
Mutex_lock(&pool->attach_mutex);
// (2.5.1) Bind the worker thread to the cpu
/*
* set_cpus_allowed_ptr() will fail if the cpumask doesn't have any
* online CPUs. It'll be re-applied when any of the CPUs come up.
*/
Set_cpus_allowed_ptr(worker->task, pool->attrs->cpumask);
/*
* The pool->attach_mutex says %POOL_DISASSOCISION remains
* stable across this function. See the comments above the
* flag definition for details.
*/
If (pool->flags & POOL_DISASSOCIATED)
Worker->flags |= WORKER_UNBOUND;
// (2.5.2) Join worker to worker_pool linked list
List_add_tail(&worker->node, &pool->workers);
Mutex_unlock(&pool->attach_mutex);
}
1.1.2 unbound worker_pool
Most of the work is performed through the normal worker_pool (for example, schedule_work(), schedule_work_on() is pushed into work in the system workqueue(system_wq)), and is finally executed by the worker in the normal worker_pool. These workers are bound to a certain CPU. Once the work is executed by the worker, it will always run on a certain CPU and will not switch the CPU.
The corresponding meaning of unbound worker_pool is that workers can be scheduled on multiple CPUs. However, he is actually bound, but the unit to which it is bound is not CPU but node. The so-called node is for a Non Uniform Memory Access Architecture (NUMA) system. NUMA may have multiple nodes, and each node may contain one or more CPUs.
The naming rules of the unbound worker_pool corresponding to the kernel thread (worker_thread()) are as follows:

So similar name is unbound worker_pool:
Shell@PRO5:/ $ ps | grep "kworker"
Root 23906 2 0 0 worker_thr 0000000000 2nd worker process for kworker/u20:2// unbound pool 20
Root 24564 2 0 0 worker_thr 0000000000 S kworker/u20:0// 0th worker process of unbound pool 20
Root 24622 2 0 0 worker_thr 0000000000 S kworker/u21:1// 1st worker process for unbound pool 21
Unbound worker_pool is also divided into two categories:
Unbound_std_wq. Each node corresponds to a worker_pool, and multiple nodes correspond to multiple worker_pools.

The corresponding topology is as follows:
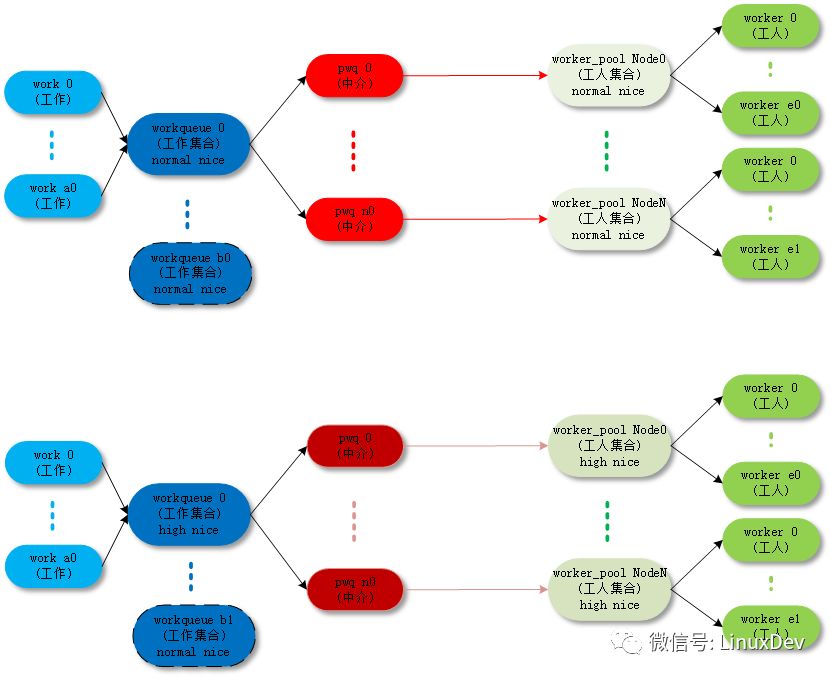
Unbound_std_wq topology
Ordered_wq. All node corresponds to a default worker_pool;
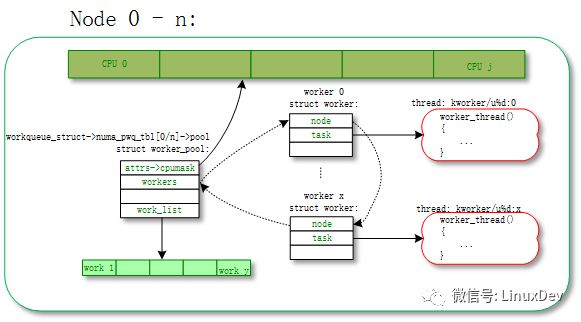
The corresponding topology is as follows:
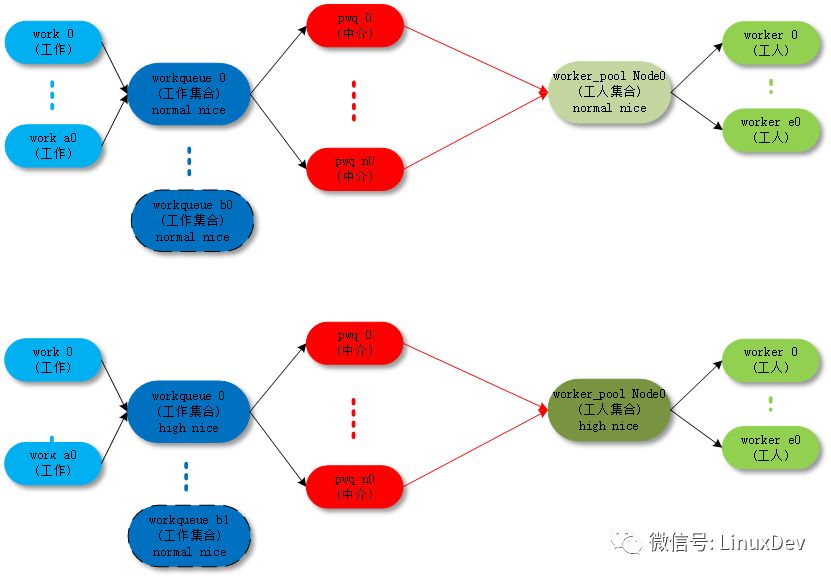
The following is an unbound worker_pool detailed creation process code analysis:
Kernel/workqueue.c:
Init_workqueues() -> unbound_std_wq_attrs/ordered_wq_attrs
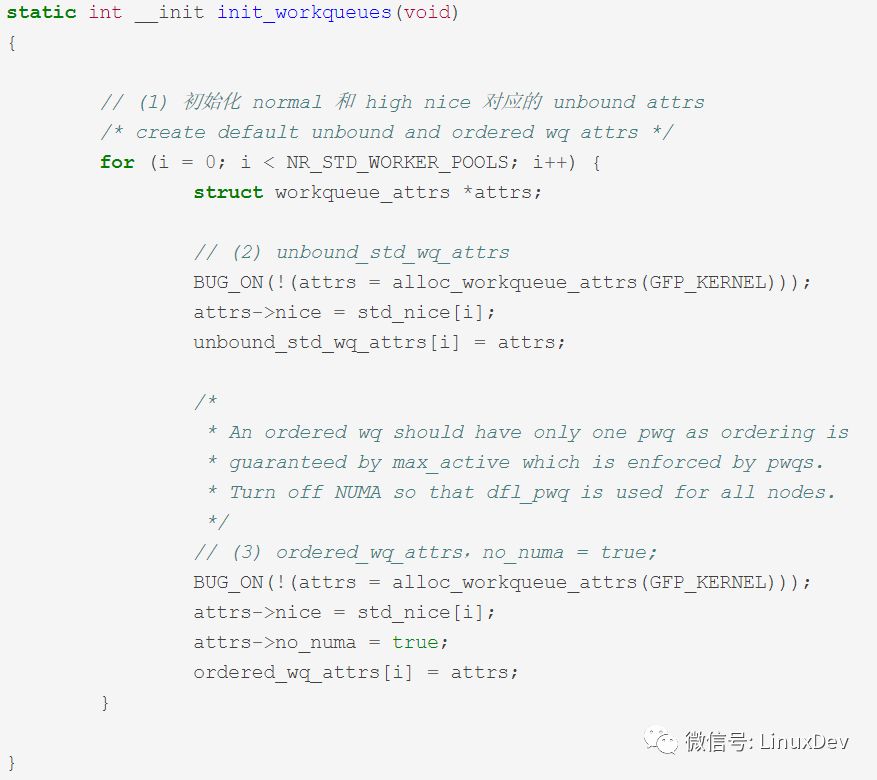
Kernel/workqueue.c:
__alloc_workqueue_key() -> alloc_and_link_pwqs() -> apply_workqueue_attrs() -> alloc_unbound_pwq()/numa_pwq_tbl_install()
Struct workqueue_struct *__alloc_workqueue_key(const char *fmt,
Unsigned int flags,
Int max_active,
Struct lock_class_key *key,
Const char *lock_name, ...)
{
Size_t tbl_size = 0;
Va_list args;
Struct workqueue_struct *wq;
Struct pool_workqueue *pwq;
/* see the comment above the definition of WQ_POWER_EFFICIENT */
If ((flags & WQ_POWER_EFFICIENT) && wq_power_efficient)
Flags |= WQ_UNBOUND;
/* allocate wq and format name */
If (flags & WQ_UNBOUND)
Tbl_size = nr_node_ids * sizeof(wq->numa_pwq_tbl[0]);
// (1) Assign workqueue_struct data structure
Wq = kzalloc(sizeof(*wq) + tbl_size, GFP_KERNEL);
If (!wq)
Return NULL;
If (flags & WQ_UNBOUND) {
Wq->unbound_attrs = alloc_workqueue_attrs(GFP_KERNEL);
If (!wq->unbound_attrs)
Goto err_free_wq;
}
Va_start(args, lock_name);
Vsnprintf(wq->name, sizeof(wq->name), fmt, args);
Va_end(args);
// (2) pwq up to worker number in worker_pool
Max_active = max_active ?: WQ_DFL_ACTIVE;
Max_active = wq_clamp_max_active(max_active, flags, wq->name);
/* init wq */
Wq->flags = flags;
Wq->saved_max_active = max_active;
Mutex_init(&wq->mutex);
Atomic_set(&wq->nr_pwqs_to_flush, 0);
INIT_LIST_HEAD(&wq->pwqs);
INIT_LIST_HEAD(&wq->flusher_queue);
INIT_LIST_HEAD(&wq->flusher_overflow);
INIT_LIST_HEAD(&wq->maydays);
Lockdep_init_map(&wq->lockdep_map, lock_name, key, 0);
INIT_LIST_HEAD(&wq->list);
// (3) Assign the corresponding pool_workqueue to workqueue
// pool_workqueue links workqueue and worker_pool
If (alloc_and_link_pwqs(wq) < 0)
Goto err_free_wq;
// (4) If it is a workqueue of type WQ_MEM_RECLAIM
// Create the corresponding rescuer_thread() kernel process
/*
* Workqueues which may be used during memory reclaim should
* have a rescuer to guarantee forward progress.
*/
If (flags & WQ_MEM_RECLAIM) {
Struct worker *rescuer;
Rescuer = alloc_worker(NUMA_NO_NODE);
If (!rescuer)
Goto err_destroy;
Rescuer->rescue_wq = wq;
Rescuer->task = kthread_create(rescuer_thread, rescuer, "%s",
Wq->name);
If (IS_ERR(rescuer->task)) {
Kfree(rescuer);
Goto err_destroy;
}
Wq->rescuer = rescuer;
Rescuer->task->flags |= PF_NO_SETAFFINITY;
Wake_up_process(rescuer->task);
}
// (5) If necessary, create a sysfs file for workqueue
If ((wq->flags & WQ_SYSFS) && workqueue_sysfs_register(wq))
Goto err_destroy;
/*
* wq_pool_mutex protects global freeze state and workqueues list.
* Grab it, adjust max_active and add the new @wq to workqueues
* list.
*/
Mutex_lock(&wq_pool_mutex);
Mutex_lock(&wq->mutex);
For_each_pwq(pwq, wq)
Pwq_adjust_max_active(pwq);
Mutex_unlock(&wq->mutex);
// (6) Add a new workqueue to the global linked workqueues
List_add(&wq->list, &workqueues);
Mutex_unlock(&wq_pool_mutex);
Return wq;
Err_free_wq:
Free_workqueue_attrs(wq->unbound_attrs);
Kfree(wq);
Return NULL;
Err_destroy:
Destroy_workqueue(wq);
Return NULL;
}
| →
Static int alloc_and_link_pwqs(struct workqueue_struct *wq)
{
Bool highpri = wq->flags & WQ_HIGHPRI;
Int cpu, ret;
// (3.1) normal workqueue
// process of pool_workqueue linking workqueue and worker_pool
If (!(wq->flags & WQ_UNBOUND)) {
// Assign the corresponding pool_workqueue to each cpu of workqueue, assign it to wq->cpu_pwqs
Wq->cpu_pwqs = alloc_percpu(struct pool_workqueue);
If (!wq->cpu_pwqs)
Return -ENOMEM;
For_each_possible_cpu(cpu) {
Struct pool_workqueue *pwq =
Per_cpu_ptr(wq->cpu_pwqs, cpu);
Struct worker_pool *cpu_pools =
Per_cpu(cpu_worker_pools, cpu);
// The normal worker_pool that was created during initialization is assigned to pool_workqueue
Init_pwq(pwq, wq, &cpu_pools[highpri]);
Mutex_lock(&wq->mutex);
// Link pool_workqueue and workqueue together
Link_pwq(pwq);
Mutex_unlock(&wq->mutex);
}
Return 0;
} Else if (wq->flags & __WQ_ORDERED) {
// (3.2) unbound ordered_wq workqueue
// process of pool_workqueue linking workqueue and worker_pool
Ret = apply_workqueue_attrs(wq, ordered_wq_attrs[highpri]);
/* there should only be single pwq for ordering guarantee */
WARN(!ret && (wq->pwqs.next != &wq->dfl_pwq->pwqs_node ||
Wq->pwqs.prev != &wq->dfl_pwq->pwqs_node),
"ordering guarantee broken for workqueue %s", wq->name);
Return ret;
} Else {
// (3.3) unbound unbound_std_wq workqueue
// process of pool_workqueue linking workqueue and worker_pool
Return apply_workqueue_attrs(wq, unbound_std_wq_attrs[highpri]);
}
}
|| →
Int apply_workqueue_attrs(struct workqueue_struct *wq,
Const struct workqueue_attrs *attrs)
{
// (3.2.1) Based on the ubound ordered_wq_attrs/unbound_std_wq_attrs
// Create the corresponding pool_workqueue and worker_pool
// Where worker_pool is not created by default, it needs to be dynamically created and the corresponding worker kernel process must be re-created.
// Created a pool_workqueue assignment to pwq_tbl[node]
/*
* If something goes wrong during CPU up/down, we'll fall back to
* the default pwq covers whole @attrs->cpumask. Always create
* it even if we don't use it immediately.
*/
Dfl_pwq = alloc_unbound_pwq(wq, new_attrs);
If (!dfl_pwq)
Goto enomem_pwq;
For_each_node(node) {
If (wq_calc_node_cpumask(attrs, node, -1, tmp_attrs->cpumask)) {
Pwq_tbl[node] = alloc_unbound_pwq(wq, tmp_attrs);
If (!pwq_tbl[node])
Goto enomem_pwq;
} Else {
Dfl_pwq->refcnt++;
Pwq_tbl[node] = dfl_pwq;
}
}
/* save the previous pwq and install the new one */
// (3.2.2) Assign temporary pwq_tbl[node] to wq->numa_pwq_tbl[node]
For_each_node(node)
Pwq_tbl[node] = numa_pwq_tbl_install(wq, node, pwq_tbl[node]);
}
||| →
Static struct pool_workqueue *alloc_unbound_pwq(struct workqueue_struct *wq,
Const struct workqueue_attrs *attrs)
{
Struct worker_pool *pool;
Struct pool_workqueue *pwq;
Lockdep_assert_held(&wq_pool_mutex);
// (3.2.1.1) If more than one corresponding unbound_pool has been created for attrs, use the existing unbound_pool
// Otherwise create a new unbound_pool based on attrs
Pool = get_unbound_pool(attrs);
If (!pool)
Return NULL;
Pwq = kmem_cache_alloc_node(pwq_cache, GFP_KERNEL, pool->node);
If (!pwq) {
Put_unbound_pool(pool);
Return NULL;
}
Init_pwq(pwq, wq, pool);
Return pwq;
}
1.2 worker
Each worker corresponds to one worker_thread() kernel thread, and one worker_pool corresponds to one or more workers. Multiple workers get work from worker_pool->worklist in the same linked list for processing.
So here are a few key points:
How does a worker handle work;
How worker_pool dynamically manages the number of workers;
1.2.1 Worker Processing Work
The process of dealing with work is mainly handled in worker_thread() -> process_one_work() , and we look specifically at the implementation of the code.
Kernel/workqueue.c:
Worker_thread() -> process_one_work()
Static int worker_thread(void *__worker){struct worker *worker = __worker;struct worker_pool *pool = worker->pool;/* tell the scheduler that this is a workqueue worker */worker->task->flags |= PF_WQ_WORKER; Woke_up:spin_lock_irq(&pool->lock);// (1) Is die/* am I supposed to die? */if (unlikely(worker->flags & WORKER_DIE)) {spin_unlock_irq(&pool->lock);WARN_ON_ONCE( !list_empty(&worker->entry));worker->task->flags &= ~PF_WQ_WORKER;set_task_comm(worker->task, "kworker/dying");ida_simple_remove(&pool->worker_ida, worker->id);worker_detach_from_pool (worker, pool);kfree(worker);return 0;}// (2) get rid of the idle state // before being woken up worker is idle state worker_leave_idle(worker);recheck:// (3) if this worker is needed to continue Execution continues, otherwise enter the idle state // need more worker conditions: (pool->worklist != 0) && (pool->nr_running == 0)// worklist work needs to be executed, and is not running now Work/* no more worker necessary? */if (!need_more_worker(pool))goto sleep;// (4 If (pool->nr_idle == 0) then start to create more workers / / Description idle There is no spare worker in the queue, first create some worker spare / * do we need to manage? */if (unlikely ( !may_start_working(pool)) && manage_workers(worker))goto recheck;/* * ->scheduled list can only be filled while a worker is * preparing to process a work or actually processing it. * Make sure nobody diddled with it while I Was sleeping. */WARN_ON_ONCE(!list_empty(&worker->scheduled));/* * Finish PREP stage. We're guaranteed to have at least one idle * worker or that someone else has already decoded the manager * role. This is Where @worker starts participating in concurrency * management if applicable and concurrency management is restored * after being rebound. See rebind_workers() for details. */worker_clr_flags(worker, WORKER_PREP | WORKER_REBOUND);do {// (5) If pool-> Worklist is not empty, remove a work from it and deal with struct work_struct *work =list_first_entry(&pool->worklist, struct work _struct, entry);if (likely(!(*(work_data_bits(work) & WORK_STRUCT_LINKED))) {/* optimization path, not strictly necessary */// (6) Perform normal workprocess_one_work(worker, work);if (unlikely (!list_empty(&worker->scheduled)))process_scheduled_works(worker);} else {// (7) The execution system is specifically scheduled for a worker's work// The ordinary work is a pool-list placed in the pool's public list. >worklist// Only some special work is specifically dispatched to a worker worker->scheduled// Include: 1. The barrier work inserted when the flush_work is executed; // Collision workmove_linked_works that is pushed from other workers to this worker. (work, &worker->scheduled, NULL);process_scheduled_works(worker);}// (8) Worker keep_working conditions: pool->worklist is not empty && (pool->nr_running <= 1)} while (keep_working (pool));worker_set_flags(worker, WORKER_PREP);supposedsleep:// (9) worker enters idle state/* * pool->lock is held and there's no work to process and no need to * manage, sleep. Workers are woken Up only while h Olding * pool->lock or from local cpu, so setting the current state * before freezing pool->lock is enough to prevent losing any * event. */worker_enter_idle(worker);__set_current_state(TASK_INTERRUPTIBLE);spin_unlock_irq(&pool->lock) };schedule();goto woke_up;}| →static void process_one_work(struct worker *worker, struct work_struct *work)__releases(&pool->lock)__acquires(&pool->lock){struct pool_workqueue *pwq = get_work_pwq(work) ;struct worker_pool *pool = worker->pool;bool cpu_intensive = pwq->wq->flags & WQ_CPU_INTENSIVE;int work_color;struct worker *collision;#ifdef CONFIG_LOCKDEP/* * It is permissible to free the struct work_struct from * inside the Function that was called from it, this we need to * take into account for lockdep too. To avoid bogus "held * lock freed" warnings as well as problems when looking into *work->lockdep_map, make a copy and use that here. */struct lockdep_map lockdep_map;lockdep_copy_map(&lockdep_map, &work->lockdep_map);#endif/* ensure we're on the Correct CPU */WARN_ON_ONCE(!(pool->flags & POOL_DISASSOCIATED) && raw_smp_processor_id() != pool->cpu);// (8.1) If work has been executed on other workers in worker_pool, // put work into corresponding In the worker's scheduled queue, execution is delayed. * * * A single work shouldn't be executed concurrently by * multiple workers on a single cpu. Check whether is * already processed the work. If so, defer the work to the * currently executing one */collision = find_worker_executing_work(pool, work);if (unlikely(collision)) {move_linked_works(work, &collision->scheduled, NULL);return;}// (8.2) Add worker to busy queue pool->busy_hash/ * claim and dequeue */debug_work_deactivate(work);hash_add(pool->busy_hash, &worker->hentry, (unsigned long)work);worker->current_work = work;worker->current_func = work->func;worker-> Current_pwq = pwq;work_color = get_work_color(work);list_del_init(&work->entry);// (8.3) If the work is in a wq that is cpu-intensive WQ_CPU_INTENSIVE// then the execution of the current work is taken out of w The dynamic scheduling of orker_pool becomes a separate thread /* * CPU intensive works don't participate in concurrency management. * They're the scheduler's responsibility. This takes @worker out * of concurrency management and the next code block will chain * execution. Of the pending work items. */if (unlikely(cpu_intensive))worker_set_flags(worker, WORKER_CPU_INTENSIVE);// (8.4) Whether or not to wake the idle worker in the UNBOUND or CPU_INTENSIVE work is determined. /normal work does not perform this operation/* * Wake up another worker if necessary. The condition is always * false for normal per-cpu workers since nr_running would always be >= 1 at this point. This is used to chain execution of the * pending work items for WORKER_NOT_RUNNING workers such as The * UNBOUND and CPU_INTENSIVE ones. */if (need_more_worker(pool))wake_up_worker(pool);/* * Record the last pool and clear PENDING which should be the last * update to @work. Also, do this inside @pool- >lock so that * PENDING and queued state change s happen together while while IRQ is * disabled. */set_work_pool_and_clear_pending(work, pool->id);spin_unlock_irq(&pool->lock);lock_map_acquire_read(&pwq->wq->lockdep_map);lock_map_acquire(&lockdep_map);trace_workqueue_execute_start(work); // (8.5) execute the work function worker->current_func(work);/* * While we must be careful to not use "work" after this, the trace * point will only record its address. */trace_workqueue_execute_end(work); Lock_map_release(&lockdep_map);lock_map_release(&pwq->wq->lockdep_map);if (unlikely(in_atomic() || lockdep_depth(current) > 0)) {pr_err("BUG: workqueue leaked lock or atomic: %s/0x% 08x/%d" " last function: %pf", current->comm, preempt_count(), task_pid_nr(current), worker->current_func);debug_show_held_locks(current);dump_stack();}/* * The following prevents a Kworker from hogging CPU on !PREEMPT * kernels, where a requeueing work item waiting for something to * event happened deadlock with stop_machine as such work item could * indefinitely requeue itse Lf while all other CPUs are trapped in * stop_machine. At the same time, report a quiescent RCU state so * the same condition doesn't freeze RCU. */cond_resched_rcu_qs();spin_lock_irq(&pool->lock);/* clear cpu Intensive status */if (unlikely(cpu_intensive))worker_clr_flags(worker, WORKER_CPU_INTENSIVE);/* we're done with it, release */hash_del(&worker->hentry);worker->current_work = NULL;worker->current_func = NULL; worker->current_pwq = NULL; worker->desc_valid = false;pwq_dec_nr_in_flight(pwq, work_color);
}
1.2.2 worker_pool dynamic management worker
How worker_pool dynamically adds or subtracts workers. This part of the algorithm is the core of CMWQ. The idea is as follows:
The workers in worker_pool have 3 states: idle, running, suspend;
If there is work in the worker_pool that needs to be processed, keep at least one running worker to handle it;
The running worker enters the blocking suspend state during the work process. In order to keep the other work executing, it needs to wake up the new idle worker to process the work.
If there is a work to be executed and a running worker is greater than one, the redundant running worker will enter the idle state.
If there is no work to execute, all workers will be in the idle state.
If you create too many workers, destroy_worker does not re-run the idle worker for 300s (IDLE_WORKER_TIMEOUT).

Detailed code can refer to the analysis of the previous section worker_thread() -> process_one_work() .
In order to track the worker's running and suspend status, it is used to dynamically adjust the number of workers. Wq Tips for using hook functions in process scheduling:
Tracing worker from running into running state: ttwu_activate() -> wq_worker_waking_up()

Tracing workers from running into suspend state:__schedule() -> wq_worker_sleeping()
Struct task_struct *wq_worker_sleeping(struct task_struct *task, int cpu){struct worker *worker = kthread_data(task), *to_wakeup = NULL;struct worker_pool *pool;/* * Rescuers, which may not have all the fields set up like normal * workers, also reach here, let's not access anything before * checking NOT_RUNNING. */if (worker->flags & WORKER_NOT_RUNNING)return NULL;pool = worker->pool;/* this can only happen on the local cpu */if (WARN_ON_ONCE(cpu != raw_smp_processor_id() || pool->cpu != cpu)) return NULL;/* * The counterpart of the following dec_and_test, implied mb, * worklist not empty test sequence is in insert_work(). * Please Read comment there. * * NOT_RUNNING is clear. This means that we're bound to and * running on the local cpu w/ rq lock held and preemption * disabled, which in turn means that none else could be * manipulating idle_list, so dereferencing Idle_list without pool * lock is safe. */// Reduces the number of running workers in worker_pool // If the worklist still has work Handling, wake-first idle worker is processed if (! Atomic_dec_and_test (& pool-> nr_running) && list_empty (& pool-> worklist)) to_wakeup = first_idle_worker (pool); return to_wakeup to_wakeup-> task: NULL;?
}
The scheduling idea of ​​worker_pool here is: if there is work to be processed, there is no more or no more worker processing to maintain a running state.
However, there is a problem here. If the work is CPU-intensive, it will not enter the suspended state, but it will occupy the CPU for a long time, so that the subsequent work is blocked for too long.
In order to solve this problem, CMWQ designed WQ_CPU_INTENSIVE. If a wq declares itself to be CPU_INTENSIVE, the current worker is detached from the dynamic schedule. For example, if it enters the suspend state, CMWQ will create a new worker and the subsequent work will be executed.
Kernel/workqueue.c:
Worker_thread() -> process_one_work()
Static void process_one_work(struct worker *worker, struct work_struct *work)__releases(&pool->lock)__acquires(&pool->lock){bool cpu_intensive = pwq->wq->flags & WQ_CPU_INTENSIVE;// (1) Set the current worker The WORKER_CPU_INTENSIVE flag // nr_running will be decremented by 1// For worker_pool, the current worker is equivalent to entering suspend state/* * CPU intensive works don't participate in concurrency management. * They're the scheduler's responsibility. This takes @ Worker out * of concurrency management and the next code block will chain * execution of the pending work items. */if (unlikely(cpu_intensive))worker_set_flags(worker, WORKER_CPU_INTENSIVE);// (2) Take a step and judge whether or not to wake up. The new worker handles work/* * Wake up another worker if necessary. The condition is always * false for normal per-cpu workers since nr_running would always be >= 1 at this point. This is used to chain execution of the * Pending work items for WORKER_NOT_RUNNING workers such as the * UNBOUND and CPU_INT ENSIVE ones. */if (need_more_worker(pool)) wake_up_worker(pool);// (3) Execute the workworker->current_func(work);// (4) Execute, clean up the WORKER_CPU_INTENSIVE flag of the current worker // Current worker Enter the running state/* clear cpu intensive status */if (unlikely(cpu_intensive))worker_clr_flags(worker, WORKER_CPU_INTENSIVE);}WORKER_NOT_RUNNING= WORKER_PREP | WORKER_CPU_INTENSIVE | WORKER_UNBOUND | WORKER_REBOUND,static inline void worker_set_flags(struct worker *worker, unsigned int flags) {struct worker_pool * pool = worker-> pool; WARN_ON_ONCE (! worker-> task = current); / * If transitioning into NOT_RUNNING, adjust nr_running * / if ((flags & WORKER_NOT_RUNNING) && (worker-> flags & WORKER_NOT_RUNNING.! )) {atomic_dec (& pool-> nr_running);} worker-> flags | = flags;} static inline void worker_clr_flags (struct worker * worker, unsigned int flags) {struct worker_pool * pool = worker-> pool; unsigned int oflags = Worker->flags;WARN_ON_ONCE(worker->task != current);worker->flags &= ~flags;/* * If transitioni Ng out of NOT_RUNNING, increment nr_running. Note * that the nested NOT_RUNNING is not a noop. NOT_RUNNING is mask * of multiple flags, not a single flag. */if ((flags & WORKER_NOT_RUNNING) && (oflags & WORKER_NOT_RUNNING))if ( !(worker->flags & WORKER_NOT_RUNNING))atomic_inc(&pool->nr_running);
}
1.2.3 CPU hotplug processing
As you can see from the previous sections, the system will create a normal worker_pool that is bound to the CPU and an unbound worker_pool that will not be bound to the CPU. The worker_pool will dynamically create workers.
What happens to the dynamic processing of worker_pool and worker in CPU hotplug? Look at the specific code analysis:
Kernel/workqueue.c:
Workqueue_cpu_up_callback()/workqueue_cpu_down_callback()
Static int __init init_workqueues(void)
{Cpu_notifier (workqueue_cpu_up_callback, CPU_PRI_WORKQUEUE_UP); hotcpu_notifier (workqueue_cpu_down_callback, CPU_PRI_WORKQUEUE_DOWN);} | → static int workqueue_cpu_down_callback (struct notifier_block * nfb, unsigned long action, void * hcpu) {int cpu = (unsigned long) hcpu; struct work_struct unbind_work; struct workqueue_struct * wq; switch (action & ~ CPU_TASKS_FROZEN) {case CPU_DOWN_PREPARE: / * unbinding per-cpu workers should happen on the local CPU * / INIT_WORK_ONSTACK (& unbind_work, wq_unbind_fn); // (1) cpu down_prepare // and the current cpu Worker shutdown on the bound normal worker_pool // As the current CPU is down, these workers will be migrated to queue_work_on (cpu, system_highpri_wq, &unbind_work) on other CPUs; // (2) Unbound wq updates to cpu changes/* Update NUMA affinity of unbound workqueues */mutex_lock(&wq_pool_mutex);list_for_each_entry(wq, &workqueues, list)wq_update_unbound_numa(wq, cpu, false);mutex_unlock(&wq_pool_mutex);/* wait for per-cpu unbinding to finish */flush_work(&unbind_work );d estroy_work_on_stack (& ​​unbind_work); break;} return NOTIFY_OK;} | → static int workqueue_cpu_up_callback (struct notifier_block * nfb, unsigned long action, void * hcpu) {int CPU = (unsigned long) hcpu; struct worker_pool * pool; struct workqueue_struct * wq ;int pi;switch (action & ~CPU_TASKS_FROZEN) {case CPU_UP_PREPARE:for_each_cpu_worker_pool(pool, CPU) {if (pool->nr_workers)continue;if (!create_worker(pool)) return NOTIFY_BAD;}break;case CPU_DOWN_FAILED:case CPU_ONLINE :mutex_lock(&wq_pool_mutex);// (3) CPU upfor_each_pool(pool, pi) {mutex_lock(&pool->attach_mutex);// If there is a WORKER_UNBOUND lockout on the normal worker_pool bound to the current CPU// rebinding Worker to worker_pool// let these workers start and bind to the current CPUif (pool->CPU == CPU) rebind_workers(pool); else if (pool->CPU < 0) restore_unbound_workers_cpumask(pool, CPU);mutex_unlock(&pool ->attach_mutex);}/* update NUMA affinity of unbound workqueues */list_for_each_entry(wq, &workqueues, list)wq_update_unbound_numa(wq, CPU, True);mutex_unlock(&wq_pool_mutex);break;}return NOTIFY_OK;
}
1.3 workqueue
The workqueue is a collection of a set of work, which can be basically divided into two types: a workqueue created by a system, and a workqueue created by a user.
Whether the system or the user's workqueue, if you do not specify WQ_UNBOUND, the default is bound to the normal worker_pool.
1.3.1 system workqueue
系统在åˆå§‹åŒ–时创建了一批默认的workqueue:system_wqã€system_highpri_wqã€system_long_wqã€system_unbound_wqã€system_freezable_wqã€system_power_efficient_wqã€system_freezable_power_efficient_wq。
åƒsystem_wq,就是schedule_work() 默认使用的。
kernel/workqueue.c:
init_workqueues()
static int __init init_workqueues(void){system_wq = alloc_workqueue("events", 0, 0);system_highpri_wq = alloc_workqueue("events_highpri", WQ_HIGHPRI, 0);system_long_wq = alloc_workqueue("events_long", 0, 0);system_unbound_wq = alloc_workqueue("events_unbound", WQ_UNBOUND, WQ_UNBOUND_MAX_ACTIVE);system_freezable_wq = alloc_workqueue("events_freezable", WQ_FREEZABLE, 0);system_power_efficient_wq = alloc_workqueue("events_power_efficient", WQ_POWER_EFFICIENT, 0);system_freezable_power_efficient_wq = alloc_workqueue("events_freezable_power_efficient", WQ_FREEZABLE | WQ_POWER_EFFICIENT, 0);}
1.3.2 workqueue 创建
详细过程è§ä¸Šå‡ 节的代ç 分æžï¼šalloc_workqueue() -> __alloc_workqueue_key() -> alloc_and_link_pwqs()。
1.3.3 flush_workqueue()
这一部分的逻辑,wq->work_colorã€wq->flush_color æ¢æ¥æ¢åŽ»çš„逻辑实在看的头晕。看ä¸æ‡‚æš‚æ—¶ä¸æƒ³çœ‹ï¼Œæ”¾ç€ä»¥åŽçœ‹å§ï¼Œæˆ–者有è°çœ‹æ‡‚了教我一下。:)
1.4 pool_workqueue
pool_workqueue åªæ˜¯ä¸€ä¸ªä¸ä»‹è§’色。
详细过程è§ä¸Šå‡ 节的代ç 分æžï¼šalloc_workqueue() -> __alloc_workqueue_key() -> alloc_and_link_pwqs()。
1.5 work
æ述一份待执行的工作。
1.5.1 queue_work()
å°†work 压入到workqueue 当ä¸ã€‚
kernel/workqueue.c:
queue_work() -> queue_work_on() -> __queue_work()
static void __queue_work(int cpu, struct workqueue_struct *wq, struct work_struct *work){struct pool_workqueue *pwq;struct worker_pool *last_pool;struct list_head *worklist;unsigned int work_flags;unsigned int req_cpu = cpu;/* * While a work item is PENDING && off queue, a task trying to * steal the PENDING will busy-loop waiting for it to either get * queued or lose PENDING. Grabbing PENDING and queueing should * happen with IRQ disabled. */WARN_ON_ONCE(!irqs_disabled());debug_work_activate(work);/* if draining, only works from the same workqueue are allowed */if (unlikely(wq->flags & __WQ_DRAINING) && WARN_ON_ONCE(!is_chained_work(wq)))return;retry:// (1) 如果没有指定cpu,则使用当å‰cpuif (req_cpu == WORK_CPU_UNBOUND)cpu = raw_smp_processor_id();/* pwq which will be used unless @work is executing elsewhere */if (!(wq->flags & WQ_UNBOUND))// (2) 对于normal wq,使用当å‰cpu 对应的normal worker_poolpwq = per_cpu_ptr(wq->cpu_pwqs, cpu);else// (3) 对于unbound wq,使用当å‰cpu 对应node çš„worker_poolpwq = unbound_pwq_by_node(wq, cpu_to_node(cpu));// (4) 如果work 在其他worker 上æ£åœ¨è¢«æ‰§è¡Œï¼ŒæŠŠwork 压到对应的worker 上去// é¿å…work 出现é‡å…¥çš„问题/* * If @work was previously on a different pool, it might still be * running there, in which case the work needs to be queued on that * pool to guarantee non-reentrancy. */last_pool = get_work_pool(work);if (last_pool && last_pool != pwq->pool) {struct worker *worker;spin_lock(&last_pool->lock);worker = find_worker_executing_work(last_pool, work);if (worker && worker->current_pwq->wq == wq) {pwq = worker->current_pwq;} else {/* meh... not running there, queue here */spin_unlock(&last_pool->lock);spin_lock(&pwq->pool->lock);}} else {spin_lock(&pwq->pool->lock);}/* * pwq is determined and locked. For unbound pools, we could have * raced with pwq release and it could already be dead. If its * refcnt is zero, repeat pwq selection. Note that pwqs never die * without another pwq replacing it in the numa_pwq_tbl or while * work items are executing on it, so the retrying is guaranteed to * make forward-progress. */if (unlikely(!pwq->refcnt)) {if (wq->flags & WQ_UNBOUND) {spin_unlock(&pwq->pool->lock);cpu_relax();goto retry;}/* oops */WARN_ONCE(true, "workqueue: per-cpu pwq for %s on cpu%d has 0 refcnt", wq->name, cpu);}/* pwq determined, queue */trace_workqueue_queue_work(req_cpu, pwq, work);if (WARN_ON(!list_empty(&work->entry))) {spin_unlock(&pwq->pool->lock);return;}pwq->nr_in_flight[pwq->work_color]++;work_flags = work_color_to_flags(pwq->work_color);// (5) 如果还没有达到max_active,将work 挂载到pool->worklistif (likely(pwq->nr_active < pwq->max_active)) {trace_workqueue_activate_work(work);pwq->nr_active++;worklist = &pwq->pool->worklist;// å¦åˆ™ï¼Œå°†work 挂载到临时队列pwq->delayed_works} else {work_flags |= WORK_STRUCT_DELAYED;worklist = &pwq->delayed_works;}// (6) å°†work 压入worklist 当ä¸insert_work(pwq, work, worklist, work_flags);spin_unlock(&pwq->pool->lock);
}
1.5.2 flush_work()
flush æŸä¸ªwork,确ä¿work 执行完æˆã€‚
怎么判æ–异æ¥çš„work å·²ç»æ‰§è¡Œå®Œæˆï¼Ÿè¿™é‡Œé¢ä½¿ç”¨äº†ä¸€ä¸ªæŠ€å·§ï¼šåœ¨ç›®æ ‡work çš„åŽé¢æ’入一个新的work wq_barrier,如果wq_barrier 执行完æˆï¼Œé‚£ä¹ˆç›®æ ‡work 肯定已ç»æ‰§è¡Œå®Œæˆã€‚
kernel/workqueue.c:
queue_work() -> queue_work_on() -> __queue_work()
/** * flush_work - wait for a work to finish executing the last queueing instance * @work: the work to flush * * Wait until @work has finished execution. @work is guaranteed to be idle * on return if it hasn't been requeued since flush started. * * Return: * %true if flush_work() waited for the work to finish execution, * %false if it was already idle. */bool flush_work(struct work_struct *work){struct wq_barrier barr;lock_map_acquire(&work->lockdep_map);lock_map_release(&work->lockdep_map);if (start_flush_work(work, &barr)) {// ç‰å¾…barr work 执行完æˆçš„ä¿¡å·wait_for_completion(&barr.done);destroy_work_on_stack(&barr.work);return true;} else {return false;}}| →static bool start_flush_work(struct work_struct *work, struct wq_barrier *barr){struct worker *worker = NULL;struct worker_pool *pool;struct pool_workqueue *pwq;might_sleep();// (1) 如果work 所在worker_pool 为NULL,说明work å·²ç»æ‰§è¡Œå®Œlocal_irq_disable();pool = get_work_pool(work);if (!pool) {local_irq_enable();return false;}spin_lock(&pool->lock);/* see the comment in try_to_grab_pending() with the same code */pwq = get_work_pwq(work);if (pwq) {// (2) 如果work 所在pwq 指å‘çš„worker_pool ä¸ç‰äºŽä¸Šä¸€æ¥å¾—到的worker_pool,说明work å·²ç»æ‰§è¡Œå®Œif (unlikely(pwq->pool != pool))goto already_gone;} else {// (3) 如果work 所在pwq 为NULL,并且也没有在当å‰æ‰§è¡Œçš„work ä¸ï¼Œè¯´æ˜Žwork å·²ç»æ‰§è¡Œå®Œworker = find_worker_executing_work(pool, work);if (!worker)goto already_gone;pwq = worker->current_pwq;}// (4) 如果work 没有执行完,å‘work çš„åŽé¢æ’å…¥barr workinsert_wq_barrier(pwq, barr, work, worker);spin_unlock_irq(&pool->lock);/* * If @max_active is 1 or rescuer is in use, flushing another work * item on the same workqueue may lead to deadlock. Make sure the * flusher is not running on the same workqueue by verifying write * access. */if (pwq->wq->saved_max_active == 1 || pwq->wq->rescuer)lock_map_acquire(&pwq->wq->lockdep_map);elselock_map_acquire_read(&pwq->wq->lockdep_map);lock_map_release(&pwq->wq->lockdep_map);return true;already_gone:spin_unlock_irq(&pool->lock);return false;
}
|| →
static void insert_wq_barrier(struct pool_workqueue *pwq, struct wq_barrier *barr, struct work_struct *target, struct worker *worker){struct list_head *head;unsigned int linked = 0;/* * debugobject calls are safe here even with pool->lock locked * as we know for sure that this will not trigger any of the * checks and call back into the fixup functions where we * might deadlock. */// (4.1) barr work 的执行函数wq_barrier_func()INIT_WORK_ONSTACK(&barr->work, wq_barrier_func);__set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(&barr->work));init_completion(&barr->done);/* * If @target is currently being executed, schedule the * barrier to the worker; otherwise, put it after @target. */// (4.2) 如果work 当å‰åœ¨worker ä¸æ‰§è¡Œï¼Œåˆ™barr work æ’å…¥scheduled 队列if (worker)head = worker->scheduled.next;// å¦åˆ™ï¼Œåˆ™barr work æ’å…¥æ£å¸¸çš„worklist 队列ä¸ï¼Œæ’å…¥ä½ç½®åœ¨ç›®æ ‡work åŽé¢// 并且置上WORK_STRUCT_LINKED æ ‡å¿—else {unsigned long *bits = work_data_bits(target);head = target->entry.next;/* there can already be other linked works, inherit and set */linked = *bits & WORK_STRUCT_LINKED;__set_bit(WORK_STRUCT_LINKED_BIT, bits);}debug_work_activate(&barr->work);insert_work(pwq, &barr->work, head, work_color_to_flags(WORK_NO_COLOR) | linked);
}
||| →
static void wq_barrier_func(struct work_struct *work){struct wq_barrier *barr = container_of(work, struct wq_barrier, work);// (4.1.1) barr work 执行完æˆï¼Œå‘出complete ä¿¡å·ã€‚complete(&barr->done);
}
2.Workqueue 对外接å£å‡½æ•°
CMWQ 实现的workqueue 机制,被包装æˆç›¸åº”的对外接å£å‡½æ•°ã€‚
2.1 schedule_work()
把work 压入系统默认wq system_wq,WORK_CPU_UNBOUND 指定worker 为当å‰CPU 绑定的normal worker_pool 创建的worker。
kernel/workqueue.c:
schedule_work() -> queue_work_on() -> __queue_work()

2.2 schedule_work_on()
在 schedule_work() 基础上,å¯ä»¥æŒ‡å®šwork è¿è¡Œçš„CPU。
kernel/workqueue.c:
schedule_work_on() -> queue_work_on() -> __queue_work()

2.3 schedule_delayed_work()
å¯åŠ¨ä¸€ä¸ªtimer,在timer 定时到了以åŽè°ƒç”¨ delayed_work_timer_fn() 把work 压入系统默认wq system_wq。
kernel/workqueue.c:
schedule_work_on() -> queue_work_on() -> __queue_work()
static inline bool schedule_delayed_work(struct delayed_work *dwork, unsigned long delay)
{return queue_delayed_work(system_wq, dwork, delay);
}
| →
static inline bool queue_delayed_work(struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay)
{return queue_delayed_work_on(WORK_CPU_UNBOUND, wq, dwork, delay);}|| →bool queue_delayed_work_on(int cpu, struct workqueue_struct *wq, struct delayed_work *dwork, unsigned long delay){struct work_struct *work = &dwork->work;bool ret = false;unsigned long flags;/* read the comment in __queue_work() */local_irq_save(flags);if (!test_and_set_bit(WORK_STRUCT_PENDING_BIT, work_data_bits(work))) {__queue_delayed_work(cpu, wq, dwork, delay);ret = true;}local_irq_restore(flags);return ret;
}
||| →
static void __queue_delayed_work(int cpu, struct workqueue_struct *wq,struct delayed_work *dwork, unsigned long delay){struct timer_list *timer = &dwork->timer;struct work_struct *work = &dwork->work;WARN_ON_ONCE(timer->function != delayed_work_timer_fn || timer->data != (unsigned long)dwork);WARN_ON_ONCE(timer_pending(timer));WARN_ON_ONCE(!list_empty(&work->entry));/* * If @delay is 0, queue @dwork->work immediately. This is for * both optimization and correctness. The earliest @timer can * expire is on the closest next tick and delayed_work users depend * on that there's no such delay when @delay is 0. */if (!delay) {__queue_work(cpu, wq, &dwork->work);return;}timer_stats_timer_set_start_info(&dwork->timer);dwork->wq = wq;dwork->cpu = cpu;timer->expires = jiffies + delay;if (unlikely(cpu != WORK_CPU_UNBOUND))add_timer_on(timer, cpu);elseadd_timer(timer);
}
|||| →
void delayed_work_timer_fn(unsigned long __data)
{struct delayed_work *dwork = (struct delayed_work *)__data;/* should have been called from irqsafe timer with irq already off */__queue_work(dwork->cpu, dwork->wq, &dwork->work);
}
å‚考资料
Documentation/workqueue.txt
EQM(ECM)
EQM series motors are designed with advanced electronic control technology, make the motor efficiency greatly increased,the external structure design of EQM series motors will maintain the similar external structure design as YZF series motors,motor accessories such as fan blades, rings or grids.brackets for EQM motors are the same as YZF series`. therefore EQM series motors can completely replace the YZF series motors without any other changes.Comparing with YZF series motors, EQM motors display an obvious advantage in energy saving. saving up to 70%.It can greatly reduce the electricity cost for motor operation and carbon dioxide emissions Not only that.due to the heating of EQM series motors themselves are very low.it would lead to the entire
refrigeration system works more efficient and make motor running more stable and reliable
Centrifugal Fan,Centrifugal Blower,Centrifugal Blower Fan,Centrifugal Air Blower
Hangzhou Jinjiu Electric Appliance Co Ltd. , http://www.jinjiufanmotor.com