Yuan Jinhui: Sharing the technical progress in the deep learning framework
Source: Microsoft Research AI headlines
Summary: On January 17, Dr. Yuan Jinhui, a fellow of the hospital, returned to Microsoft Research Asia to give a report titled “Building the Strongest Deep Learning Engine†and shared the technical progress in the deep learning framework.
On January 17, Dr. Yuan Jinhui, a fellow of the hospital, returned to Microsoft Research Asia to give a report titled “Building the Strongest Deep Learning Engine†and shared the technical progress in the deep learning framework. The report mainly explains what is the strongest computing engine? Why is dedicated hardware fast? What are the problems with large-scale dedicated hardware? What problems should the software architecture solve?
First, let's open a brain: imagine what an ideal deep learning engine should look like, or what is the ultimate form of deep learning engine? See what this will bring to the deep learning framework and AI-specific chip development.
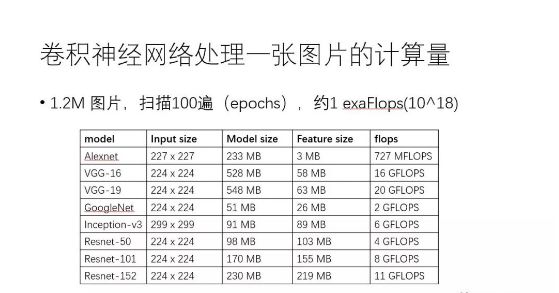
Taking the well-known convolutional neural network CNN as an example, you can feel how much computational power is required to train the deep learning model. The table below lists the memory capacity and floating-point calculations required for a typical CNN model to process a picture. For example, the VGG-16 network requires 16Gflops to process an image. It is worth noting that the CNN is trained based on the ImageNet dataset. The dataset has a total of about 1.2 million images. The training algorithm needs to scan the dataset for 100 epochs, which means 10^18 floating-point calculations, namely 1exaFlops. A simple calculation reveals that it takes several years to train such a model based on a CPU core clocked at 2.0 GHz.
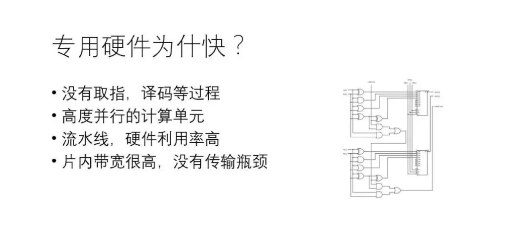
Dedicated hardware is faster than general-purpose hardware (such as CPU, GPU) for a variety of reasons, including: (1) general-purpose chips generally undergo "fetch-decode-execute" (even including "fetch data") steps to complete once Operation, dedicated hardware greatly reduces the overhead of "finger-decode", and the data arrives and executes; (2) the dedicated hardware control circuit has low complexity, and can integrate more useful devices for the operation under the same area. It takes thousands of clock cycles to complete the general hardware in one clock cycle; (3) pipeline parallelism is supported in dedicated hardware and general hardware, and hardware utilization is high; (4) dedicated hardware has high on-chip bandwidth. Most of the data is transmitted on-chip. Obviously, if you don't consider physical reality, no matter what neural network, no matter how large the problem is, it is the most efficient way to implement a set of dedicated hardware. The question is, does this work?
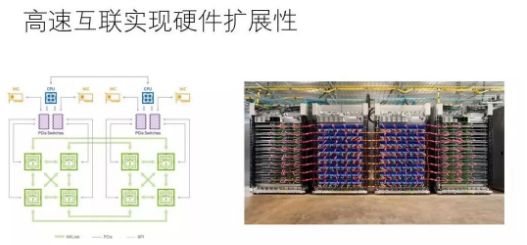
In reality, both general-purpose hardware (such as GPU) and dedicated hardware (such as TPU) can be connected together through high-speed interconnect technology, and multiple devices can be coordinated by software to complete large-scale computing. Using state-of-the-art interconnect technology, the transmission bandwidth between devices and devices can reach 100Gbps or more, which is one or two orders of magnitude lower than the internal bandwidth of the device. Fortunately, if the software is "provisioned properly", it may be under this bandwidth condition. Make the hardware calculations saturated. Of course, the "following properly" technology is extremely challenging. In fact, the faster a single device is, the harder it is to "fit and match" multiple devices.
The current deep learning generally adopts the stochastic gradient descent algorithm (SGD). Generally, a GPU processes a small piece of data in only 100 milliseconds. The key to the problem is whether the "provisioning" algorithm can be used in 100 milliseconds. The GPU is ready to process the next piece of data. If it can, then the GPU will remain in the computing state. If not, the GPU will pause intermittently, which means the device utilization is reduced. Theoretically it is possible, there is a concept called Arithmetic intensity, that is, flops per byte, which represents the amount of operation on a byte of data, as long as the amount of operation is large enough, meaning that one byte can be consumed. With enough calculations, even if the transmission bandwidth between devices is lower than the internal bandwidth of the device, it is possible to make the device fully loaded. Further, if a device is used that is faster than the GPU, then the time to process a piece of data is lower than 100 milliseconds, such as 10 milliseconds. Under a given bandwidth condition, the "provisioning" algorithm can use 10 milliseconds for the next time. Are you ready to calculate? In fact, even with GPUs that are not as fast (as opposed to dedicated chips such as TPU), the current mainstream deep learning framework has been overwhelming in some scenarios (such as model parallelism).
A common deep learning software framework must be able to "provision" hardware most efficiently for any given neural network and available resources. This requires addressing three core issues: (1) resource allocation, including computational core, memory, and transport. The allocation of three resources of bandwidth requires comprehensive consideration of locality and load balancing; (2) generation of correct data routing (equivalent to the connection problem between dedicated hardware as previously conceived); (3) efficient operation mechanism, Perfect coordination of data handling and calculations with the highest hardware utilization.
In fact, these three questions are very challenging. I will not discuss their solutions in this article. If we can solve these problems, what good will it be?
Suppose we can solve the three software problems mentioned above, then we can "have both fish and bear's paw": the software is flexible, the hardware is highly efficient, and a deep learning task is given. Users do not need to reconnect. It's great to be able to enjoy the performance of "infinitely dedicated hardware." Even more exciting is that when this software is implemented, dedicated hardware can be simpler and more efficient than all current AI chips. Readers can first imagine how to achieve this wonderful prospect.

Let us reiterate a few points: (1) software is really critical; (2) we are more interested in the optimization of the macro level (between devices and devices); (3) there is an ideal implementation of the deep learning framework, just as The most round circle in Plato's mind, of course, the existing deep learning framework is still far apart; (4) companies in all walks of life, as long as they have data-driven business, they all need a "brain" of their own. "It should not be exclusive to only a few giant companies."

Incremental Encoder is commonly used, and Absolute Encoder is used if there are strict requirements on position and zero position. Servo system should be analyzed in detail, depending on the application situation. Commonly used incremental encoder for speed measurement, which can be used for infinite accumulation measurement; Absolute encoder is used for position measurement, and the position is unique (single or multiple turns). Finally, it depends on the application situation and the purpose and requirements to be realized.
Incremental Linear Encoders,Linear Optical Encoder,Linear Position Encoder,Encoder Bearing Tester
Yuheng Optics Co., Ltd.(Changchun) , https://www.yhenoptics.com