User Behavior Modeling Framework Based on Attention Mechanism and Its Application in Recommendation Fields
This paper proposes a modeling framework for user heterogeneous behavior sequences based on attention mechanism and applies it to the recommended scenarios. We group different types of user behavior sequences into different subspaces. We use self-attention to model the interaction between behaviors. In the end, we get the user's behavioral characterization, and the downstream task can use the basic attention model to make more directional decisions. We try to predict multiple types of user behavior simultaneously using the same model to achieve the effect of predicting single-type behavior by multiple individual models. In addition, because we do not use RNN, CNN and other methods in our method, this method can have faster training speed while improving the effect.
Research Background
A person is defined by the behavior he exhibits. Accurate and in-depth research on users is often at the heart of many business issues. In the long run, as more and more types of behaviors can be recorded, the platform side needs to be able to better understand users by integrating various user behaviors, thus providing better personalized services.
For Alibaba, global marketing with consumer operations as its core concept is a data & technology driven solution that combines users' ecological behavior data to help brands achieve new marketing. Therefore, the study of user behavior has become a very core issue. Among them, the big challenge comes from whether the user's heterogeneous behavior data can be processed more finely.
In this context, this paper proposes a general user characterization framework, trying to fuse different types of user behavior sequences, and use this framework to verify the effects in the recommended tasks. In addition, we also hope that we can use this user characterization to achieve different downstream tasks through multitasking.
Related work
Heterogeneous Behavior Modeling: User characteristics are typically represented by manual feature engineering. These manual features are dominated by aggregated features or untimed id feature sets.
Single Behavior Sequence Modeling: User sequence modeling typically uses RNN (LSTM/GRU) or CNN + Pooling. RNN is difficult to parallel, training and prediction time is long, and Internal Memory in LSTM cannot remember a specific behavior record. CNN also cannot retain specific behavioral characteristics and requires deeper levels to establish the effects of arbitrary behavior.
Heterogeneous data characterization learning: reference knowledge mapping and multi-modal characterization research work, but usually have very obvious mapping supervision. In our mission, there is no obvious mapping between heterogeneous behaviors like the task of image caption.
The main contributions of this paper are as follows:
Trying to design and implement a method that can integrate users' multiple time series behavior data, the more innovative idea is to propose a solution that considers heterogeneous behavior and timing simultaneously, and gives a relatively simple implementation.
Using Google's self-attention mechanism to remove the restrictions of CNN and LSTM, the network training and prediction speed will be faster, and the effect can be slightly improved.
This framework is easy to extend. It can allow more different types of behavioral data access, while providing opportunities for multitasking learning to compensate for behavioral sparsity.
ATRank program introduction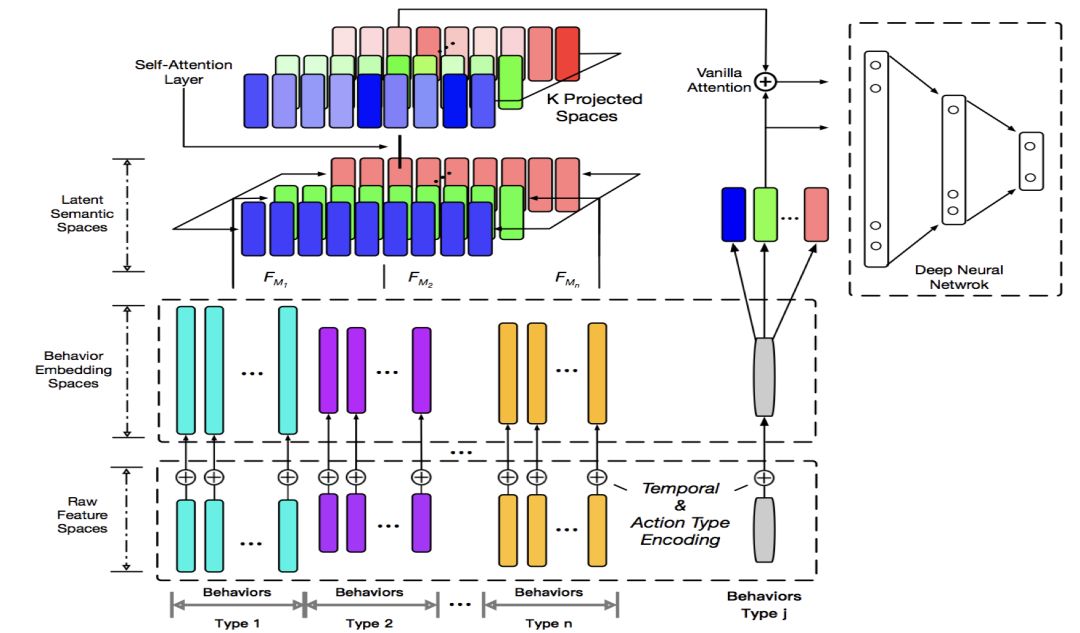
The framework for the entire user representation includes the original feature layer, the semantic mapping layer, the Self-Attention layer, and the target network.
The semantic mapping layer allows different behaviors to be compared and interacted in different semantic spaces. The Self-Attention layer makes the individual behavior itself a record that takes into account the effects of other behaviors. The target network can accurately find relevant user behaviors for predictive tasks through Vanilla Attention. Through the idea of ​​Time Encoding + Self Attention, our experiments show that it can replace CNN/RNN to describe sequence information, which can make the model training and prediction faster.
Behavior grouping
A user's behavior sequence can be described by a triple (action type, target, time). We first group the different behaviors of users according to the target entity, as shown in the bottom of the figure, the different color group. Such as merchandise behavior, coupon behavior, keyword behavior, and so on. The action type can be click/collection/addition, purchase/use, and the like.
Each entity has its own different attributes, including real-valued features and discrete id-like features. The action type is the id class, and we also discretize the time. The three parts are added to get the vector group of the next layer.
That is, the encoding of a behavior = custom target encoding + lookup (discretion time) + lookup (action type).
Because the amount of information of the entity is different, the length of the vector coded by each group of behaviors is different, which actually means that the amount of information contained in the behavior is different. In addition, some parameters may be shared between different behaviors, such as shop id, category id such as lookup table, which can reduce certain sparsity and reduce the total amount of parameters.
The main purpose of the grouping is not only convenient but also related to implementation. Because variable length, heterogeneous processing is difficult to achieve efficiently without grouping. And later we can see that our method does not actually force the behavior to be sorted by time.
2. Semantic space mapping
This layer enables the semantic communication between heterogeneous behaviors by linearly mapping heterogeneous behaviors into multiple semantic spaces. For example, the space to be expressed in the frame diagram is the atomic semantic space composed of red, green and blue (RGB), and the following composite colors (different types of user behavior) are projected into each atomic semantic space. In the same semantic space, the same semantic components of these heterogeneous behaviors are comparable.
A similar idea actually appears in the knowledge graph representation. In the field of NLP, there have been some studies this year that the attention mechanism of multi-semantic space can improve the effect. One point that personally thinks is that if there is no multi-semantic space, the so-called semantic neutrality problem will occur. The simple understanding is that two different kinds of behaviors a, b may only be related in some field, but when the attention score is a global scalar, a, b will increase each other in less relevant fields. Impact, but this effect is diminished in highly relevant areas.
Although from an implementation point of view, this layer is all behavior coding to a unified space mapping, the mapping method can be linearly nonlinear, but in fact, for the latter network layer, we can see it as a The large space is divided into multiple semantic spaces, and self-attention operations are performed in each subspace. So from an explanation point of view, we simply describe this mapping directly as a projection of multiple sub-semantic spaces.
3. Self Attention layer
The purpose of the Self Attention layer is actually to make each behavior of the user from an objective representation into a representation in the user's memory. Objective characterization means that, for example, A and B do the same thing, and the behavior itself may be the same. However, in this memory of A and B, the intensity and clarity may be completely different. This is because A and B have different behaviors. In fact, observing the softmax function, the more similar behaviors are done, the more their representations will be averaged. Behaviors that bring different experiences will make it easier to retain your information. So self attention actually simulates the characterization of an behavior that is influenced by other behaviors.
In addition, Self Attention can have multiple layers. It can be seen that a layer of Self-Attention corresponds to the first-order behavioral influence. Multi-layers will consider multi-order behavioral effects. This network structure draws on google's self-attention framework.
The specific calculation method is as follows:
S is the output of the entire semantic layer, and Sk is the projection of the kth semantic space. After the self-attention, the representation formula of the kth semantic space is:
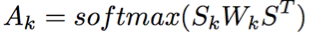

The attention function here can be seen as a bilinear attention function. The final output is that these space vectors are stitched together before joining a feedforward network.
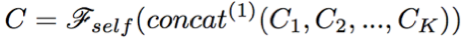
4. Target network
The target network will be customized with downstream tasks. The tasks involved in this paper are the task of user behavior prediction and click prediction of recommended scenes, using point-wise way for training and prediction.
The gray bar in the frame diagram represents any kind of behavior to be predicted. We also convert this behavior through embedding, projection, etc., and then do vanilla attention with the behavior vector that the user represents the output. The final Attention vector and target vector will be sent to a Ranking Network. Features that are strongly related to other scenes can be placed here. This network can be arbitrary, it can be wide & deep, deep FM, pnn. In the experiment of the paper, we are simply dnn.
Offline experimentIn order to compare the effects of the framework on single behavior predictions, we experimented on the public dataset of amazon purchase behavior.
The training convergence results are as follows:
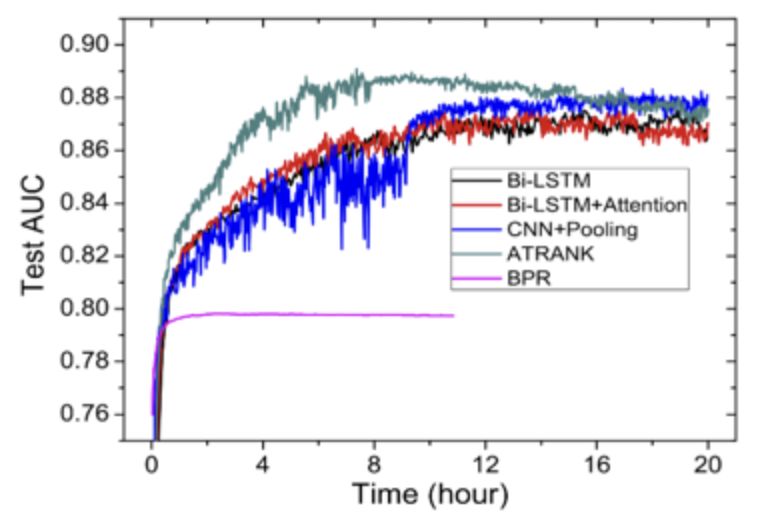
The average user AUC is as follows:
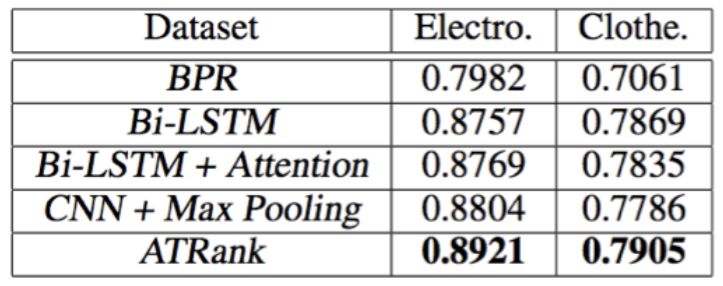
Experimental conclusion: self-attention + time encoding can also better replace the encoding method of cnn+pooling or lstm in behavior prediction or recommendation task. Training time can be 4 times faster than cnn/lstm. The effect can be slightly better than other methods.
Case StudyTo get a deeper understanding of the meaning of Self-Attention in multiple spaces, we did a simple case study on the Amazon dataset. As shown below:
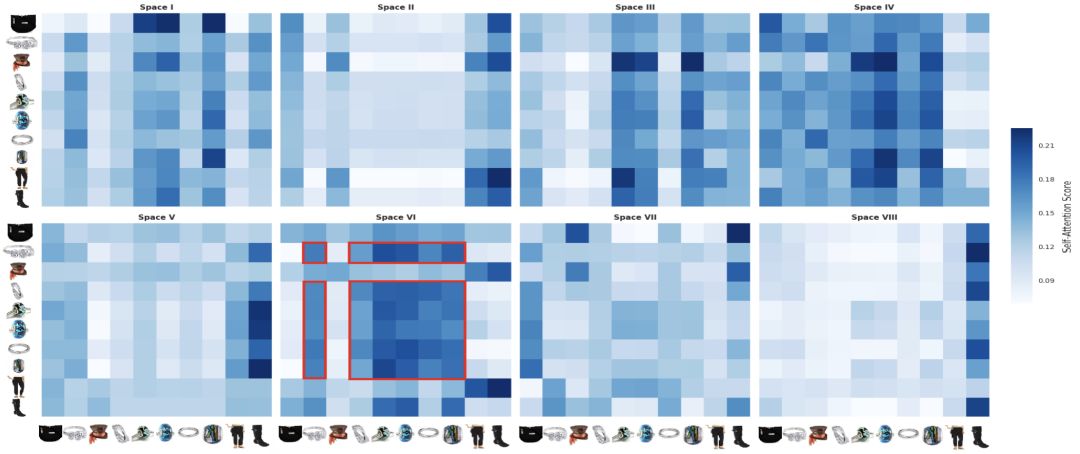
As we can see from the figure, the focus of different spaces is very different. For example, the trend of the attention score for each of the spaces I, II, III, VIII is similar. This may be the main effect of the overall behavior of different behaviors. Other spaces, such as VII, tend to form dense squares, and we can see that this is because these goods belong to the same category.
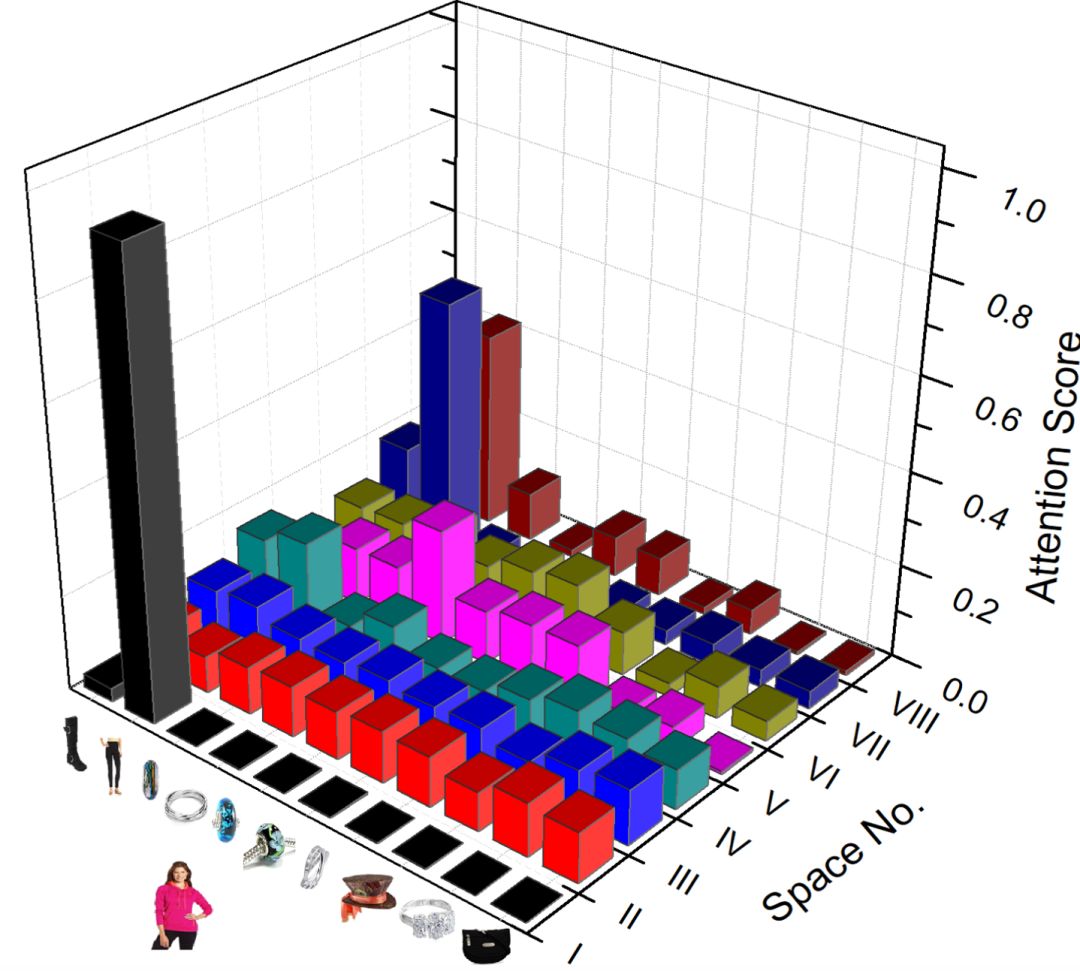
The figure below is the score of vanilla attention in different semantic spaces.
In the paper, we collected offline E-commerce users to train the purchase of goods, click collection and purchase, coupon collection, keyword search for three behaviors, and also predict these three different behaviors at the same time. Among them, the user's product behavior record is the whole network, but the final product click behavior to be predicted is the real exposure and click record of a recommended scene in the store. Coupons, keyword training and predictions are all online behaviors.
We constructed seven training modes for comparison. The single behavior sample predicts the same behavior (3 types), the full behavior multiple model predicts the single behavior (3 types), and the full behavior single model predicts the full behavior (1 type). In the last experimental setup, we cut each of the three prediction tasks into mini-batch, and then unified shuffle and training.
The experimental results are as follows:
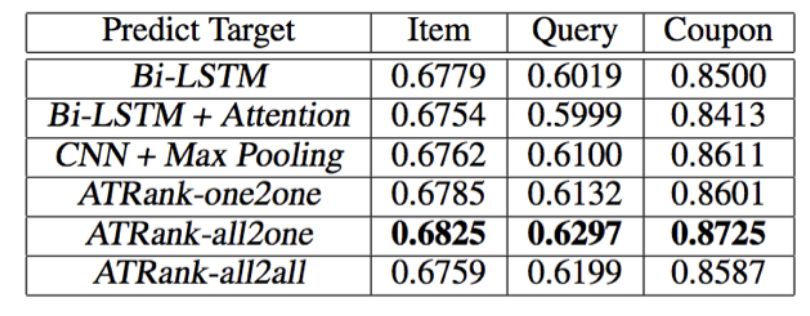
All2one is three models to predict three tasks, and all2all is a single model to predict three tasks, that is, three tasks share all parameters without their own exclusive parts. Therefore, all2all is slightly lower than all2one. When we train multitasking all2all, we will perform a full random shuffle after each of the three different prediction tasks are batched. There are still many ways to improve the multi-task training in the text. There are some good methods to learn from the frontier, which is one of the directions we are currently trying.
Experiments show that our framework can achieve better recommendation/behavior prediction by incorporating more behavioral data.
to sum upThis paper proposes a general user characterization framework to fuse different types of user behavior sequences and validate them in recommended tasks.
In the future, we hope to combine more practical business scenarios and richer data to create a flexible and scalable user characterization system to better understand users, provide better personalized services, and output more comprehensive data capabilities.
Deep Cycle Modular LiFePO4 Battery Pack For Boats&Ships
marine battery pack,shipping LiFePO4 battery pack,dual purpose ship battery,walmart boat battery pack,ship battery,deep cycle ship battery,ship battery pack,power wheels battery upgrade
Shandong Huachuang Times Optoelectronics Technology Co., Ltd. , https://www.dadncell.com