Talking about the Design of Metadata Service of Distributed Block Storage
In general, we classify distributed storage into three types based on stored access interfaces and application scenarios, including distributed block storage, distributed file storage, and distributed object storage.
The main application scenarios of distributed block storage include:
1. Virtualization: Hypervisors such as KVM, VMware, XenServer, and cloud platforms like Openstack, AWS. The role in which the block is stored is the storage that supports the virtual disk in the virtual machine.
2. Database: such as MySQL, Oracle, etc. Many DBAs run the database's data disks on a shared block storage service, such as distributed block storage. In addition, many customers run the database directly in the virtual machine.
3. Containers: Containers have become more widely used in the enterprise in recent years. In general, applications running in a container are stateless, but in many application scenarios, applications also have data persistence requirements. Applications can choose to persist data into the database, or they can choose to persist data to a shared virtual disk. This requirement corresponds to Kubernetes, which is the Persistent Volume feature.

Today I will focus on how SmartX builds distributed block storage. Since the establishment of SmartX in 2013, we have accumulated 5 years of R&D experience in distributed block storage. So today, in addition to sharing how SmartX implements our own distributed block storage ZBS, we will also detail our distribution. Some thoughts and choices in the development of block storage. In addition, we will introduce the future planning of our products.
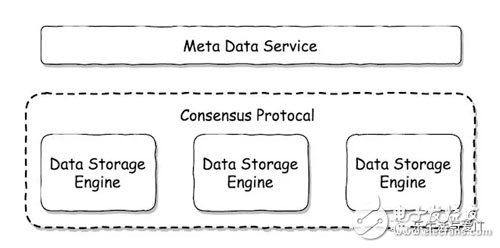
In a broad sense, distributed storage usually needs to solve three problems, namely metadata service, data storage engine, and consistency protocol.
Among them, the functions provided by the metadata service generally include: cluster member management, data addressing, copy allocation, load balancing, heartbeat, garbage collection, and the like. The data storage engine is responsible for resolving data storage on a single machine, as well as local disk management, disk failure handling, and more. Each data storage engine is isolated. Between these isolated storage engines, a coherency protocol needs to be run to ensure that access to the data meets our desired consistency state, such as strong consistency, weak consistency, and order. Consistent, linear consistency, and more. We choose a suitable coherence protocol according to different application scenarios. This protocol will be responsible for the synchronization of data between different nodes.
With these three parts, we basically mastered the core of a distributed storage. The differences between different distributed storage systems are basically different from the choice of these three aspects.
Next, I will introduce from each of these three aspects how we think about the SmartX ZBS system design, and finally decide which type of technology and implementation method to use.

First let's introduce the metadata service. Let's first talk about our need for metadata services.
The so-called metadata is "data of data", such as where the data is placed, which servers are in the cluster, and so on. If the metadata is lost, or the metadata service is not working properly, the entire cluster's data cannot be accessed.
Because of the importance of metadata, the first requirement for metadata is reliability. Metadata must be kept in multiple copies, and the metadata service needs to provide Failover capabilities.
The second requirement is high performance. Although we can optimize the IO path so that most IO requests do not need to access the metadata service, there are always some IO requests that need to modify the metadata, such as data distribution and so on. To avoid metadata operations becoming a bottleneck in system performance, the response time of metadata operations must be short enough. At the same time, due to the continuous expansion of the cluster size of distributed systems, there are certain requirements for the concurrency of metadata services.
The last requirement is lightweight. Since most of the usage scenarios of our products are private deployments, that is, our products are deployed in the customer's data center, and are operated by the customers themselves, rather than our operation and maintenance personnel. This scene is completely different from many Internet companies operating their own products. So for ZBS, we put more emphasis on the entire system, especially the lightweight of metadata services, and the ability to operate. We expect metadata services to be lightweight enough to allow a mix of metadata services and data services. At the same time, we hope that most of the operation and maintenance operations can be done automatically by the program, or the user only needs to perform simple operations on the interface. If you understand HDFS, the module of the metadata service in HDFS is called Namenode, which is a very heavyweight module. The Namenode needs to be deployed independently on a physical server, and the hardware requirements are very high, and it is very difficult to operate and maintain. Whether it is an upgrade or an active/standby switchover, it is a very heavy operation, which is very easy to cause failure due to operational problems. .
The above is our demand for metadata services. Next, let's take a look at the specific methods to construct a metadata service.

When it comes to storing data, especially storing structured data, the first thing we think of is a relational database, such as MySQL, and some mature KV storage engines, such as LevelDB, RocksDB, and so on. But the biggest problem with this type of storage is the inability to provide reliable data protection and Failover capabilities. Although LevelDB and RocksDB are very lightweight, they can only save data on a single machine. Although MySQL also provides some master and backup solutions, we believe that MySQL's master and backup solution is a too cumbersome solution, and lacks a simple automated operation and maintenance solution, so it is not a very good choice.
Second, let's take a look at some distributed databases such as MongoDB and Cassandra. Both distributed databases address data protection and provide a Failover mechanism. However, they do not provide an ACID mechanism, so it is cumbersome to implement in the upper layer and requires extra work. Secondly, these distributed databases are also relatively complex in operation and maintenance, and are not very easy to automate operation and maintenance.
There is also an option to implement a framework yourself based on the Paxos or Raft protocol. But the cost of this implementation is very large, not a very cost-effective choice for a startup. And we started our business in 2013, when Raft was just just proposed.
The fourth is to choose Zookeeper. Based on the ZAB protocol, Zookeeper provides a stable and reliable distributed storage service. But the biggest problem with Zookeeper is that the amount of data that can be stored is very limited. In order to improve the access speed, Zookeeper caches all the stored data in memory. Therefore, the size of the data supported by the metadata service is severely limited by the memory capacity of the server, making the metadata service impossible to be lightweight. Nor can it be deployed with a mix of data services.
Finally, there is another way based on the Distributed Hash Table (DHT) method. The benefit of this method does not need to save the location of the data copy in the metadata, but is calculated according to the consistency hash, which greatly reduces the storage pressure and access pressure of the metadata service. However, the problem of using DHT loses control over the location of the data copy. In the actual production environment, it is very easy to cause data imbalance in the cluster. At the same time, in the operation and maintenance process, if you need to add nodes, remove nodes, add disks, remove disks, because the hash ring will change, some data needs to be redistributed, which will generate unnecessary data in the cluster. Migration, and the amount of data is often very large. This operation and maintenance operation occurs almost daily in a relatively large-scale environment. Large-scale data migration can easily affect the performance of online business, so DHT makes operation and maintenance operations very troublesome.
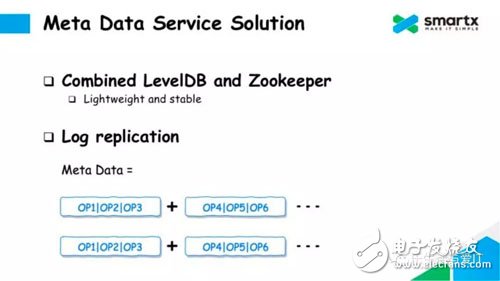
The methods described above all have various problems and cannot be used directly. Finally, ZBS chose to use LevelDB (which can also be replaced with RocksDB) and Zookeeper to solve the problem of metadata service. First of all, these two services are relatively lightweight; secondly, LevelDB and Zookeeper are also very stable in production.
We used a mechanism called Log ReplicaTIon that would take advantage of both LevelDB and Zookeeper while avoiding their own problems.
Here we briefly introduce Log ReplicaTIon. Simply put, we can think of data or state as a set of historical operations on a set of data operations, and each operation can be recorded by serializing it into a Log. If we can get all the Logs and repeat them according to the operations recorded in the Log, then we can completely restore the state of the data. Any program that owns a Log can recover data by replaying the Log. If we copy the Log, it is actually equivalent to copying the data. This is the most basic idea of ​​Log ReplicaTIon.
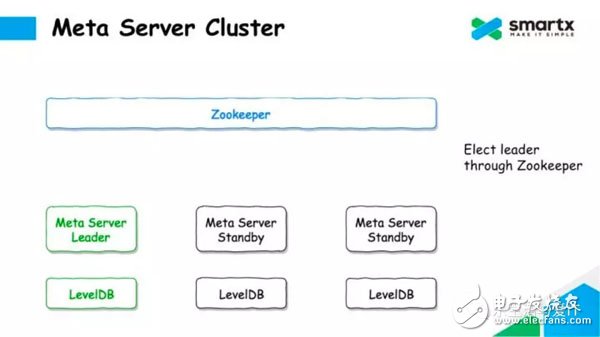
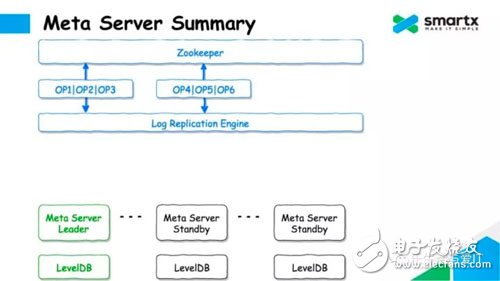
Let's take a look at how ZBS uses the Zookeeper + LevelDB to complete the Log ReplicaTIon operation. First, there are many Meta Servers in the cluster, and each Server runs a LevelDB database locally. The Meta Server selects the host through Zookeeper, selects a Leader node to respond to the metadata request, and the other Meta Server enters the Standby state.
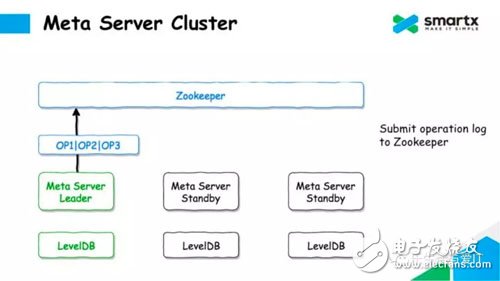
When the leader node receives the update operation of the metadata, it serializes the operation into a set of operation logs and writes the set of logs to Zookeeper. Since Zookeeper is multi-copy, once Log data is written to Zookeeper, it means that Log data is safe. At the same time, this process also completes the replication of the Log.
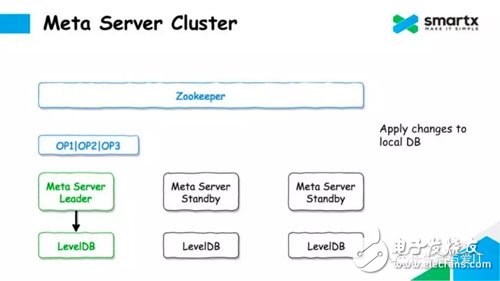
When the log is successfully submitted, Meta Server can submit the modification of the metadata to the local LevelDB at the same time. Here, LevelDB stores a full amount of data without storing it in Log form.
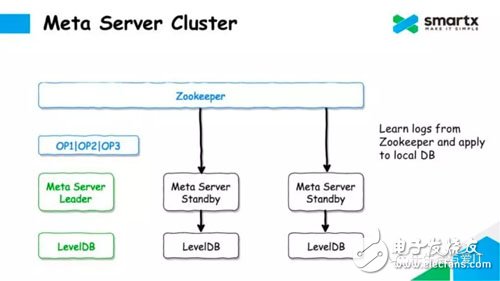
For non-Leader Meta Server nodes, the Log will be pulled asynchronously from Zookeeper, and the Log will be converted to metadata operation by deserialization, and these modifications will be submitted to the local LevelDB. This ensures that each Meta Server can hold a complete metadata.
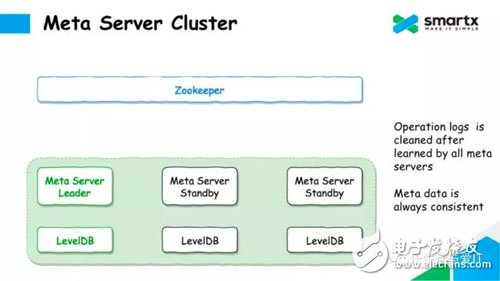
As mentioned earlier, the capacity of Zookeeper to store data is limited by the amount of memory. In order to prevent Zookeeper from consuming too much memory, we periodically clean up the Log in Zookeeper. As long as the Log has been synchronized by all Meta Servers, the Log saved in ZooKeeper can be deleted to save space. Usually we only save 1GB of Log on Zookeeper, which is enough to support the metadata service.

The logic of Failover is also very simple. If the Leader node fails, the other surviving Meta Server re-selects the owner through Zookeeper and selects a new Meta Leader. This new Leader will first synchronize all the logs that have not been consumed from Zookeeper and submit them to the local LevelDB, and then you can provide metadata services externally.
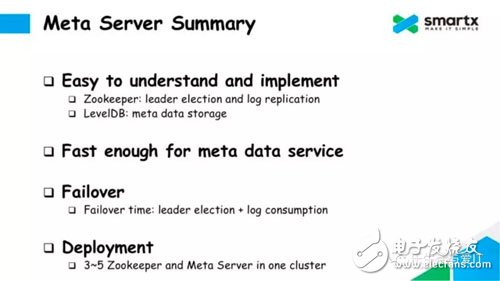
Now let's summarize the features of the metadata service implementation in ZBS.
First of all, this principle is very easy to understand and very simple to implement. Zookeeper is responsible for selecting the master and Log Replication, and LevelDB is responsible for the storage of local metadata. The logic behind this is to split the logic as much as possible and reuse the implementation of existing projects as much as possible.
Second, the speed is fast enough. The performance of Zookeeper and LevelDB itself is good, and in production, we run Zookeeper and LevelDB on the SSD. In the actual test, the modification of the single-dimensional data is done in the millisecond level. In the concurrent scenario, we can batch the metadata modification log to improve the concurrency.
In addition, this approach supports Failover, and Failover is also very fast. Failover's time is the time when the owner and Log synchronization are synchronized, and the metadata service can be restored in seconds.
Finally, let's talk about deployment. When deploying online, we typically deploy 3 or 5 instances of Zookeeper services and at least 3 instances of Meta Server services to meet metadata reliability requirements. Metadata services are very resource intensive and can be deployed in a mix with other services.
The above are some basic principles. Let's take a look at the specific implementation of metadata services inside ZBS.
We encapsulate the Log Replication logic described above in a Log Replication Engine, which includes operations such as selecting a master, submitting a log to Zookeeper, and synchronizing data to LevelDB to further simplify development complexity.
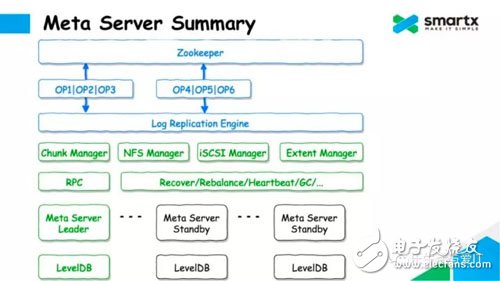
Based on the Log Replication Engine, we implemented the entire Meta Sever logic, including Chunk Manager, NFS Manger, iSCSI Manager, Extent Manager and many other management modules, all of which can manage specific parts through the Log Replication Engine. Metadata. The RPC module is an externally exposed interface of the Meta Server and is responsible for receiving external commands and forwarding them to the corresponding Manager. For example, create/delete files, create/delete virtual volumes, and more. In addition, Meta Server also contains a very complex scheduler module, which contains various complex allocation strategies, recovery strategies, load balancing strategies, and heartbeat, garbage collection and other functions.
The above is an introduction to the metadata service part.
Shenzhen MovingComm Technology Co., Ltd. , https://www.movingcommtech.com