Target Learning Countermeasure Based on Black Box Speech Recognition for Machine Learning Algorithm
Recent research by Google's brain has shown that any machine learning classifier can be deceived, giving incorrect predictions. Deep loop networks have achieved some success in automatic speech recognition (ASR) systems, but many have demonstrated that small anti-jamming can deceive deep neural networks. At present, the work on deceiving the ASR system is mainly focused on white-box attacks. Alzantot et al. prove that black box attacks using genetic algorithms are feasible.
In the paper presented by the UC Berkeley Machine Learning Team, a new black box attack field was introduced, especially in deep nonlinear ASR systems that can output any length of conversion. The authors propose a black box attack method that combines genetic algorithms with gradient estimation to produce better against samples than separate algorithms.
In the study, the genetic algorithm is applied to the phrase and sentence; the noise is limited to the high frequency domain to improve the similarity of the sample; and when the confrontation sample is close to the target, the gradient estimation is more effective than the genetic algorithm. Weighing, opening new doors for future research.
The following is an excerpt from the paper:

Introduction to confrontational attacks
Because of the strong expressive power of neural networks, they are well adapted to a variety of machine learning tasks, but they are vulnerable to hostile attacks on more than multiple network architectures and data sets. These attacks cause the network to misclassify the input by adding small perturbations to the original input, while human judgment is not affected by these perturbations.
So far, more work has been done to generate anti-samples for image input than in other fields, such as the voice system field. From personalized voice assistants, such as Amazon's Alexa and Apple's Siri, to in-vehicle voice command technology, one of the main challenges facing such systems is to correctly judge what users are saying and correctly interpret these words. These systems better understand the user, but there is a potential problem with targeted attacks against the system.
In automatic speech recognition (ASR) systems, deep loop networks have made impressive advances in speech transcription applications. Many people have shown that small anti-jamming can deceive deep neural networks to make a false prediction of a particular target. The current work on spoofing ASR systems focuses on white-box attacks where model architectures and parameters are known.
Adversarial Attacks: The input form of machine learning algorithms is a numerical vector. This is called a confrontational attack by designing a special input to make the model output an erroneous result. According to the attacker's understanding of the network, there are different ways to perform hostile attacks:
White box attack: Full understanding of the model and training set; white box attacks are the most successful given a network parameter, such as Fast Grandient Sign Method and DeepFool;
Black box attack: I don't know about the model, I don't know or know much about the training set; however, the attacker can access all the parameters of the network, which is unrealistic in practice. In a black box setup, when an attacker can only access the logic or output of the network, it is difficult to consistently create a successful hostile attack. In some special black box settings, if an attacker creates a model that is an approximation or approximation model of the target model, the white box attack method can be reused. Even if the attack can be transferred, more technologies are needed to solve this task in some areas of the network.
Attack strategy:
Gradient-based method: FGSM fast gradient method;
Optimization-based approach: use well-designed raw inputs to generate confrontation samples;
Past research
In previous research work, Cisse et al. developed a generic attack framework for working in a variety of models including images and audio. Compared to images, audio provides a bigger challenge to the model. Although convolutional neural networks can act directly on the pixel values ​​of an image, ASR systems typically require extensive preprocessing of the input audio.
The most common is the Mel-Frequency Conversion (MFC), which is essentially a Fourier transform of the sampled audio file, which converts the audio into a spectogram that shows the frequency as a function of time, as shown in the DeepSpeech model below, using the spectogram as the initial input. . When Cisse et al. applied their method to the audio samples, they encountered a roadblock that was backpropagated through the MFC conversion layer. Carlini and Wagner overcome this challenge by developing a way to pass gradients through the MFC layer.
They applied the method to the Mozilla DeepSpeech model (a complex, iterative, character-level network that decodes 50-character translations per second). They have achieved impressive results, generating more than 99.9% of the sample, similar to 100% of the target attack, although the success of this attack opened a new door for white-box attacks, but in real life, opponents usually don’t know Model architecture or parameters. Alzantot et al. demonstrated that target attacks against ASR systems are possible, using genetic algorithms to iteratively apply noise to audio samples. This attack is performed on a voice command classification model and is lightweight. A convolution model for classifying 50 different word phrases.
Research in this paper
This paper uses a black box attack and combines genetic algorithm and gradient estimation to create targeted anti-audio to implement the spoofing ASR system. The first phase of the attack is performed by a genetic algorithm, which is an optimization method that does not require a gradient. The candidate sample population is iterated until a suitable sample is generated. To limit excessive mutations and unwanted noise, we use momentum mutations to update the standard genetic algorithm.
The second stage of the attack uses gradient estimation because the gradient of a single audio point is estimated, thus allowing finer noise to be set as the hostile sample approaches the target. The combination of these two methods provides a similarity of 94.6% of audio files and 89.25% of target attack similarity after 3000 iterations. The difficulty in more complex deep speech systems is the attempt to apply black box optimization to a deeply layered, highly nonlinear decoder model. Nevertheless, the combination of two different methods and momentum mutations has brought new success to this task.
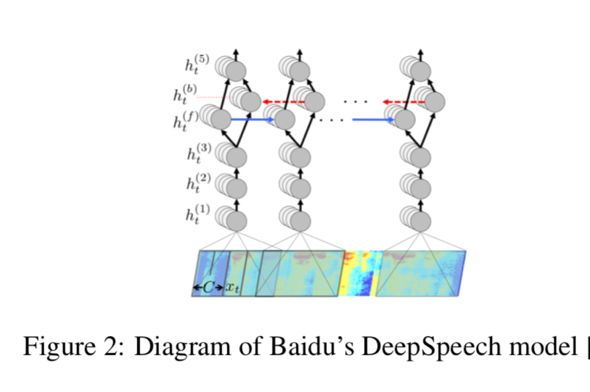
Data and methods
Dataset: The attacked dataset gets the top 100 audio samples from the Common Voice test set. For each one, randomly generate a 2-word target phrase and apply our black box method to build the first confrontation sample. The sample in each data set is a .wav file that can be easily deserialized into a numpy array. Our algorithm works directly on numpy arrays to avoid the difficulty of dealing with problems.
Victim Model: The model we attacked was the open source Baidu deep speech model implemented in Mosilla, Tensorflow. Although we can use the full model, we still see it as a black box attack, only accessing the output logic of the model. After performing an MFC conversion, the model consists of a 3-layer convolution, followed by a bidirectional LSTM, and finally a fully connected layer.
Genetic Algorithms: As mentioned earlier, Alzantot et al. demonstrated the success of black box combat attacks on speech-to-text systems using standard genetic algorithms. A genetic algorithm with a loss of CTC is effective for problems of this nature because it is completely independent of the gradient of the model.
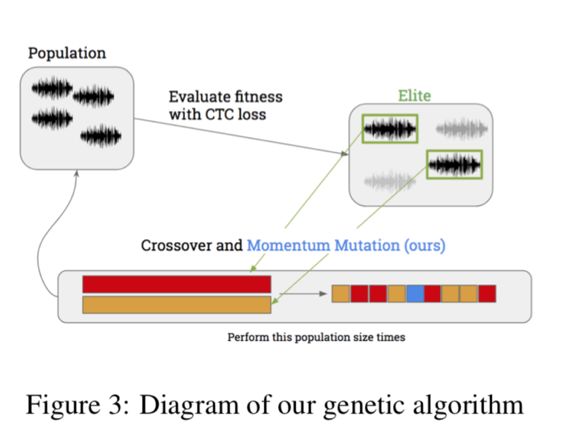
Gradient estimation: When the target space is large, the genetic algorithm works well, and relatively more mutation directions may be beneficial. The advantage of these algorithms is that they can effectively search a large amount of space. However, when the decoded distance and target decoding are below a certain threshold, it is necessary to switch to the second phase. At this time, the gradient evaluation technique is more effective, the anti-sample is already close to the target, and the gradient estimation makes a trade-off for more informational interference. The gradient evaluation technique was derived from a paper by NiTIn Bhagoji in 2017 on the study of black box attacks in the field of images.
Results and conclusions
Evaluation Criteria: Two main methods are used to evaluate the performance of the algorithm; one is the accuracy of the exact enemy audio samples being decoded to the desired target phrase; for this we use the Levenshtein distance or the minimum character edit distance. The second is to determine the similarity between the original audio samples and the hostile audio samples.
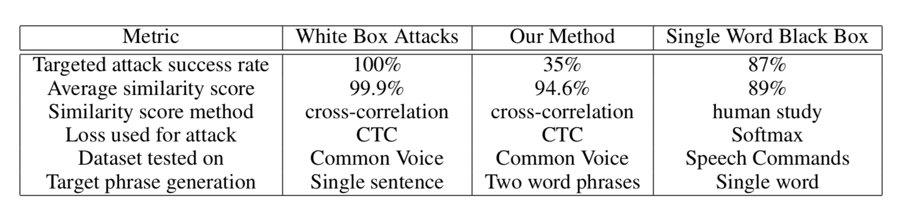
Experimental result
In the audio sample we run the algorithm, 89.25% similarity was obtained between the final decoded phrase and the target using the Levenshtein distance; the final hostile sample and the original sample had a correlation of 94.6%. After 3000 iterations, the average final Levenshtein distance was 2.3, 35% of the hostile samples were accurately decoded in less than 3000 iterations, and 22% of the hostile samples were accurately decoded in less than 1000 iterations.
The performance of the algorithm proposed in this paper is different from the data in the table. Running the algorithm in several iterations can produce a higher success rate. In fact, there is a clear trade-off between the success rate and the similarity rate. Adjust the threshold to meet the different needs of the attacker.
Contrast white box attacks, black box attacks on single words (classification), and our proposed method: by the overlap of the two waveforms, we can see the similarity between the original audio samples and the confrontation samples, as shown in the following figure, 35 The % attack is a success that emphasizes the fact of the black box, and the attack is very effective in addition to certainty.
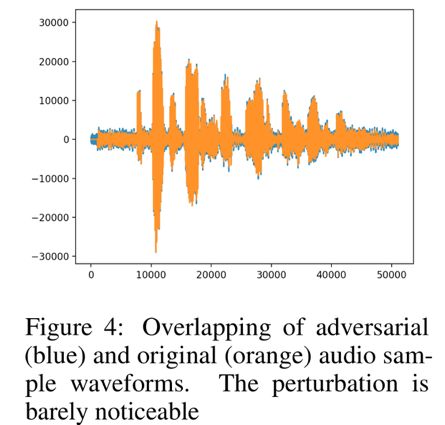
Experimental results
We implemented black box confrontation in the process of combining genetic algorithm and gradient estimation, which can produce better samples than each algorithm alone.
From the initial use of genetic algorithms, the transcription of most audio samples was nearly perfect, while maintaining a high degree of similarity. Although this is largely a conceptual verification, the research in this paper demonstrates that a black box model using a direct method can achieve targeted confrontation attacks.
In addition, the addition of momentum mutations and the addition of noise at high frequencies improve the effectiveness of our method, emphasizing the advantages of combining genetic algorithms with gradient estimation. Limiting noise to high frequency domains increases our similarity. By combining all of these methods, we can achieve our highest results.
In summary, we have introduced this new field of black box attack, combined with existing and novel methods, can demonstrate the feasibility of our method and open a new door for future research.
This 48 port USB charging station is used for the safe charging of iPhoneX, Samsung, Xiaomi, Huawei, laptop, tablet and other equipment. Portable -with a mini version of the family size desktop charger, plus compact size and lightweight weight make multiple USB charger stations very suitable for travel. Automatically detect and secure -automatically identify and adjust the best charging speed of the device. It will always collect it in the fastest and safest way. The USB charger has high current, charging and short -circuit protection, which can extend the battery life of the equipment. Environmental protection -compatibility, charging objects are not restricted, avoid using multiple chargers. Spend AC to USB data cables to USB charging sockets to meet the charging device. To MP3, MP4, DV, Bluetooth -free, all kinds of mobile phones, digital cameras and other digital products all 5V power supply costs.

48 Port Type-C Charger,Multiport Usb Charger,Usb Wall Charger Power Hub,48 Ports Usb Charging Station
shenzhen ns-idae technology co.,ltd , https://www.szbestchargers.com